过去几个月,“龙虾”类智能体产品经历了一轮从狂热到理性的过程。英特尔中国区技术部总经理高宇认为,这正是讨论“智能体 PC”的时机:智能体时代的大门已经打开,但要让它从工程师和极客的“玩具”,变成大多数人都能使用的工具,行业需要在硬件、软件、产品和生态上共同补齐短板。
英特尔给出的方向是端云混合 AI,即让云端大模型负责更复杂、更长上下文、更高智能的任务,让本地 AI 模型承担一部分固定流程、隐私敏感和低延时任务,再通过智能路由机制在端侧和云端之间自动分配任务。在其看来,这将是智能体 PC 普及的关键。
智能体 PC:不是更快的 PC,而是“数字分身”
英特尔这次提出了“智能体 PC”的概念,并解释称这并不是简单在 AI PC 上跑几个本地模型,而是面向智能体使用方式重新设计的 PC 形态。
传统 PC 是人类使用的工具。用户需要学习操作系统、应用软件、文件目录和各种功能按钮,本质上是人去“服务”电脑。智能体 PC 则反过来。它更像是人的数字分身,能够理解用户目标、学习用户习惯、记住任务和偏好,并主动帮助用户完成工作。用户不再需要一步步操作软件,而是说出目标,由智能体负责规划和执行。
二者的核心差别在于:传统 PC 是人操作机器,智能体 PC 是 AI 替人完成任务。
传统 PC 依赖键盘、鼠标和应用图标,用户需要自己打开软件、切换窗口、查找文件、整理信息,并全程在线操作;智能体 PC 则通过自然语言理解用户目标,自动拆解任务、调用工具、执行流程,并在必要时反问、确认和提醒。
传统 PC 不记得用户是谁,也不了解用户习惯;智能体 PC 则需要具备长期记忆,能记住用户偏好、任务上下文、说话风格、工作节奏,以及尚未完成的事项。
在应用形态上,传统 PC 呈现的是一个个独立软件,用户在 Word、Excel、浏览器、会议工具之间来回切换;智能体 PC 则把应用隐藏在任务背后,用户看到的是任务流和工作流。
因此,传统 PC 更像一个被动工具,而智能体 PC 更像一个能持续执行、异步工作、自动整理信息并输出结论的数字助手。
英特尔认为,智能体 PC 需要具备四项核心能力:一是本地任务闭环,能够自主完成复杂流程,不再依赖用户一步步操作;二是长期记忆和自主进化,能记住用户偏好、习惯和未完成事项,越用越懂用户;三是端云混合推理,让本地模型处理固定流程、低延时和隐私敏感任务,把复杂推理和长上下文任务交给云端大模型;四是本地安全护栏,确保高隐私数据和高危操作始终可控。
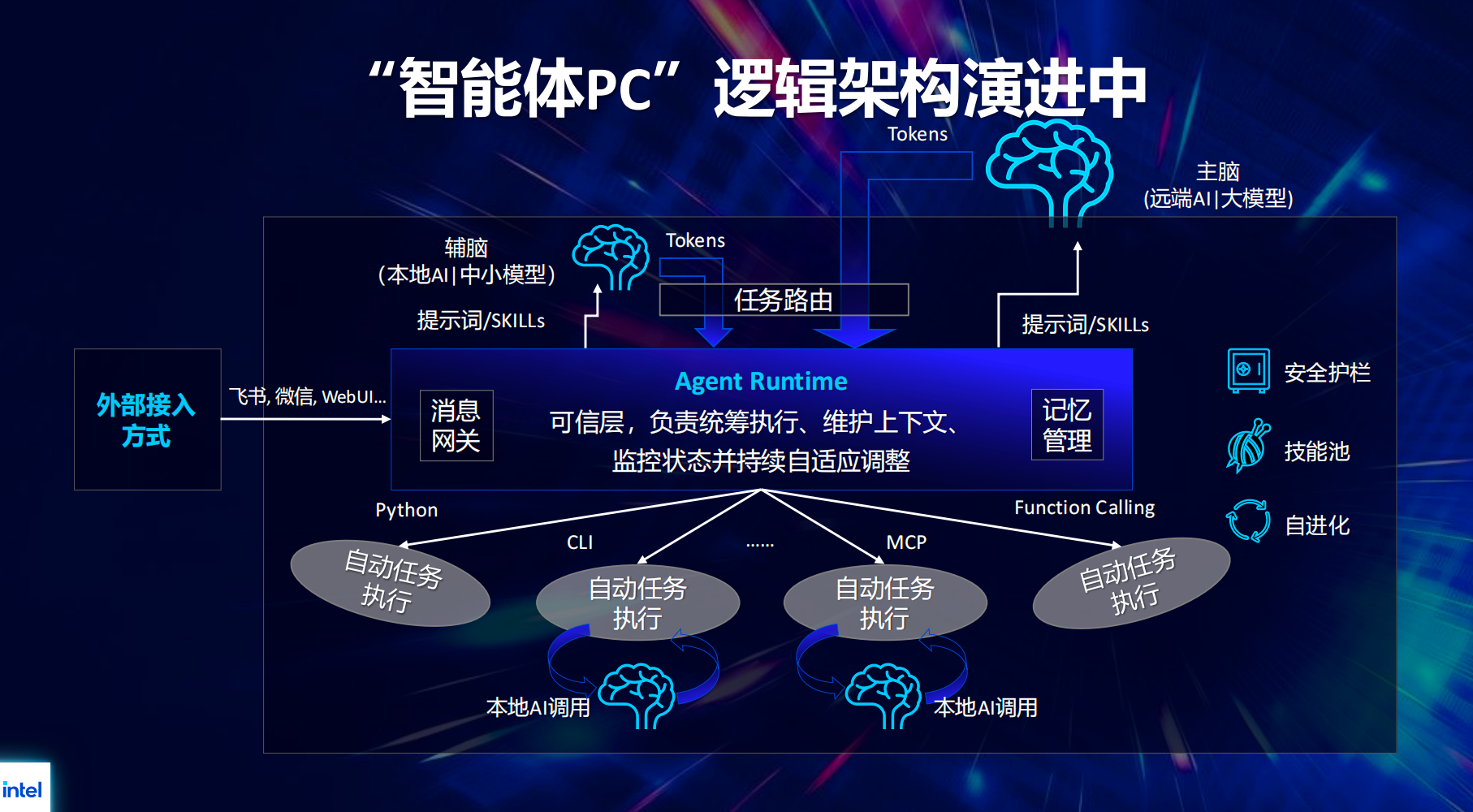
更形象地来说,如果把智能体 PC 看成一个虚拟人,它的软件架构可以拆成五个模块:
思考模块像大脑,由 AI 模型驱动,负责理解和推理。
调度模块像身体,由智能体核心逻辑驱动,负责任务调度、上下文维护和状态监控。
执行模块像四肢,通过 Python、命令行脚本、MCP 服务、Function Calling、本地 API 或 SDK 等方式完成任务。
通信和交互模块像五官,接入微信、飞书、本地 WebUI 等入口,并逐渐走向多模态交互,不再只依赖键盘和鼠标。
记忆模块则像人脑记忆体,负责存储用户偏好、历史任务和关键上下文。
在常见执行流中,用户通过微信、飞书或本地 WebUI 提交需求,消息网关将需求拆解并封装成系统提示词,交给云端 AI 模型推理。模型完成任务分解后,再通过不同执行器调用工具执行。执行结果会再次交给大模型分析,判断任务完成度,并规划下一步动作。这个过程会循环往复,直到任务完成。
必要时,系统还会调用 Skill。Skill 可以理解为大模型的“指南”和“说明书”,帮助模型在特定任务中更稳定、更符合预期。如果任务中产生了关键信息,也会通过记忆模块持久化保存。这基本是目前 OpenClaw 等智能体系统的共同运行逻辑。
为什么必须端云混合?
答案很简单:云端太贵,本地还不够聪明
云端 AI 能力更强,支持更长上下文,也更适合复杂推理任务。但它的问题也明显:成本高、存在隐私顾虑,而且在 Token 经济火热之后,云端 AI 能力和响应速度并不总是稳定。
端侧 AI 可以降低 Token 消耗,也能减少隐私数据外发,适合处理固定流程、本地文件、语音转文字、OCR 等任务。但端侧模型智能水平仍然和云端大模型有差距。即便把 120B 模型通过量化方式强行跑在端侧设备上,在任务完成度和质量上,仍然难以完全追上云端更大规模模型,而且硬件成本也高,特别是在内存价格高企的背景下并不适合普及。
因此,英特尔认为正确方向不是端侧替代云端,也不是所有任务都上云,而是端云协同。
更具体地说,智能体 PC 需要一个本地“辅脑”。它可以是运行在 AI PC 本地的中小尺寸模型,用来分担云端“主脑”的一部分推理工作。相对固定、不容易出错、隐私敏感或低延时要求高的任务,可以交给本地辅脑完成;复杂推理和长上下文任务,再交给云端主脑。
本地辅脑不只是跑一个小语言模型,还可以承担大量专项 AI 任务。例如,当智能体需要执行语音转文字任务时,可以调用本地 ASR 模型,而不必再把音频传到云端。这样既降低费用,也减少延时。
同时,系统还需要任务路由机制,由智能决策器判断任务类型,决定调用云端主脑还是本地辅脑。
英特尔希望,通过这套机制,未来至少 30%以上的任务可以放在本地运行,从而同时提升可靠性并节省 Token 费用。
英特尔给出三档智能体 PC 硬件路线
要让智能体 PC 从极客玩具变成大众工具,硬件价格和形态必须足够现实。英特尔给出的方案,是用不同 CPU 平台覆盖入门、主流和旗舰三档市场。
第一档是第三代英特尔酷睿处理器 Wildcat Lake 平台,面向入门市场,提供 40 TOPS 算力,可满足部分本地 AI 需求。英特尔将其定位为智能体 PC 的入门 CPU 选择。
第二档是第三代英特尔酷睿 Ultra 处理器 Panther Lake 家族,分为 8 核和 16 核版本。其中 8 核产品可提供最高 100 TOPS 算力,已经可以在本地运行 Qwen3.5、Qwen3.6 家族中的部分模型,承担本地辅脑能力。
第三档是旗舰酷睿 Ultra X 系列,采用 12 Xe CPU 设计,AI 算力可达 180 TOPS。英特尔认为,这一平台可以在端侧胜任 35B MoE 模型,并提供更好的 Token 速度和用户体验。
在内存配置上,英特尔认为 32GB 是相对合理的主流选择,经济条件允许则可以选择 64GB。得益于统一内存架构和灵活可调显存技术,32GB 系统中最高可将 92%以上内存分配给显存,约 27GB 可作为显存使用,足以全量载入 35B 模型,并实现 128K 以上上下文窗口。入门配置则可以使用 16GB,甚至 12GB 内存,用于运行中小尺寸模型,以降低成本和功耗。
MoE 模型的特点是拥有多个专家,但不同专家被激活的概率并不相同,经常会出现“热专家”和“冷专家”。英特尔强调了 AI SSD 技术的思路,即把不常使用的冷专家卸载到 SSD 中,需要时再从 SSD 动态加载。这对 SSD 性能提出了很高要求,包括顺序读写、随机读写以及软件优化。这类技术的意义在于,让更大模型有机会在成本更可控的端侧设备上运行,而不是全部依赖昂贵内存。
据悉,当前英特尔与合作伙伴群联已经实现 AI SSD 针对第三代英特尔酷睿 Ultra 系列处理器的卸载和加速。
在产品形态上,英特尔认为 Mini PC 是智能体 PC 的一个好形态,但绝不是唯一形态。轻薄笔记本会是智能体 PC 最重要的大众化载体,因为它离普通用户最近,也最容易普及。除此之外,一体机、AI NAS、AI Box、边缘网关,甚至其他系统集成设备,都可能成为智能体 PC 的不同形态。