用了快十年 ES 文件浏览器,今年彻底受不了了。打开就是信息流,操作三步弹一次广告,烂到 Play Store 都下架了。当然 Play Store 上文件管理器不少,但翻了一圈发现:能用的都只是"文件浏览器",没有一个真正把 AI 能力融进文件管理场景的。
所以我自己写了一个:素流,主打跟我前一个素系列产品素言一样,杜绝广告和追踪,简洁、高效、好用。
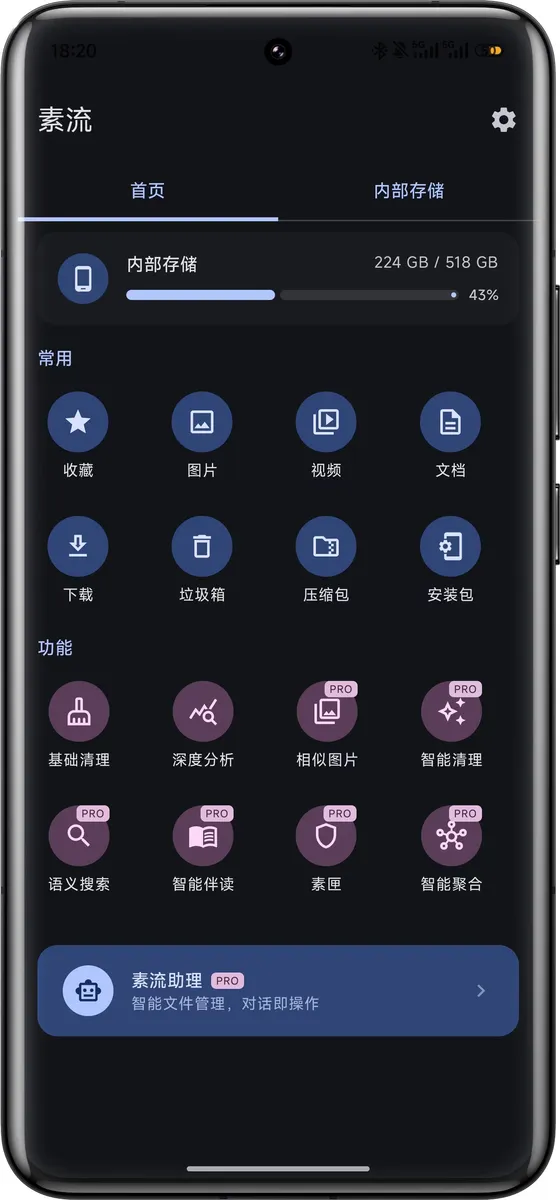
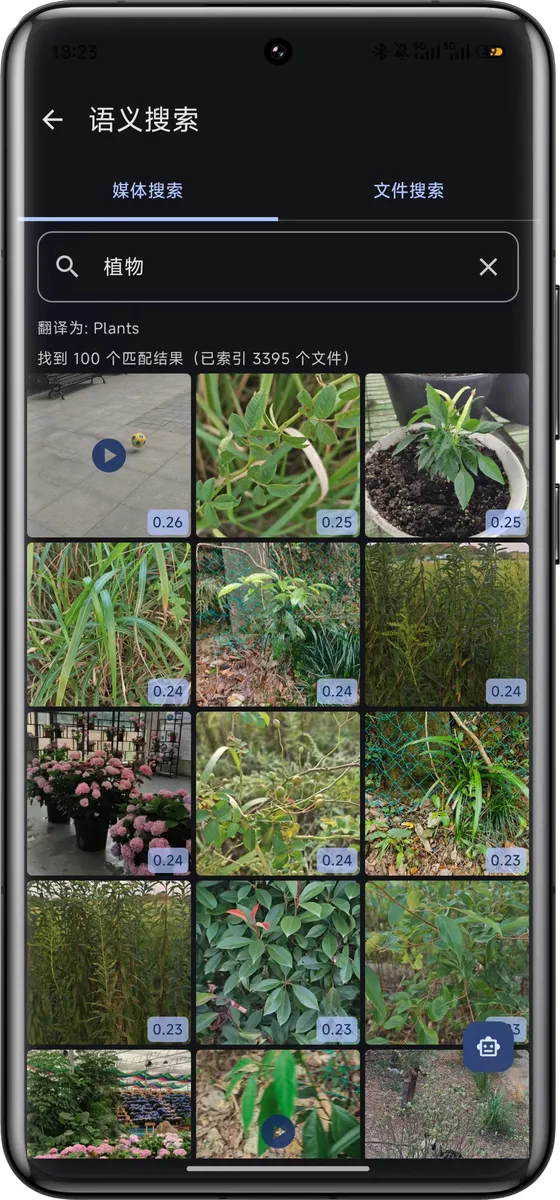
它首先是一个干净、快、功能完整的文件管理器(多标签页、跨目录剪贴板、压缩文件免解压直开、ePub/PDF 内置阅读、零广告零追踪,基础版免费),但核心差异化在于:端侧 AI 语义理解 + Agent 对话式操作——用自然语言搜图、智能识别近重复文件、对话式批量整理,这些是传统文件管理器做不到的事。
举个例子:你说"把下载目录里所有发票截图和 PDF ,按日期重命名后移到 Finance 文件夹",它会告诉你找到了哪些文件、打算怎么做,你确认后才执行。
技术上比较有意思的几个点:
-
端侧语义检索的模型选型:MobileCLIP + 翻译小模型 vs ChineseCLIP/多语言 CLIP
这个选型纠结了挺久。直觉上用 ChineseCLIP 或者多语言 CLIP 一步到位最省事,但实际跑下来发现不行:
- ChineseCLIP / multilingual-CLIP 模型体积大,量化后精度损失明显,而且视觉编码能力比 OpenAI 原版 CLIP 系列弱一截
- MobileCLIP 是 Apple Research 开源的移动端优化 CLIP 模型( CVPR 2024 ,模型本身平台无关,ONNX 导出后 Android 直接跑),视觉编码质量高、推理快、模型小,但只支持英文文本编码
最终方案是:MobileCLIP 做视觉编码 + Marian 翻译小模型把中文 query 翻成英文再做文本编码。两个模型加起来的体积比一个 ChineseCLIP 还小,而且视觉理解能力更强。翻译模型走的是 Helsinki-NLP 的 Marian ,int8 量化后 encoder + decoder 合计约 140 MB ,对比 ChineseCLIP 动辄 500MB+ 的体积仍然有优势,而且推理延迟在端侧可接受。
等于用"小模型组合"打败了"大一统模型",在端侧资源受限的场景下这个思路挺有效的。
-
Agent 架构——云端 LLM 只负责意图理解和步骤规划( BYOK 模式,用户自带 API Key ),所有文件操作在端侧执行。AI 知道你想做什么,但不知道你文件里有什么。
-
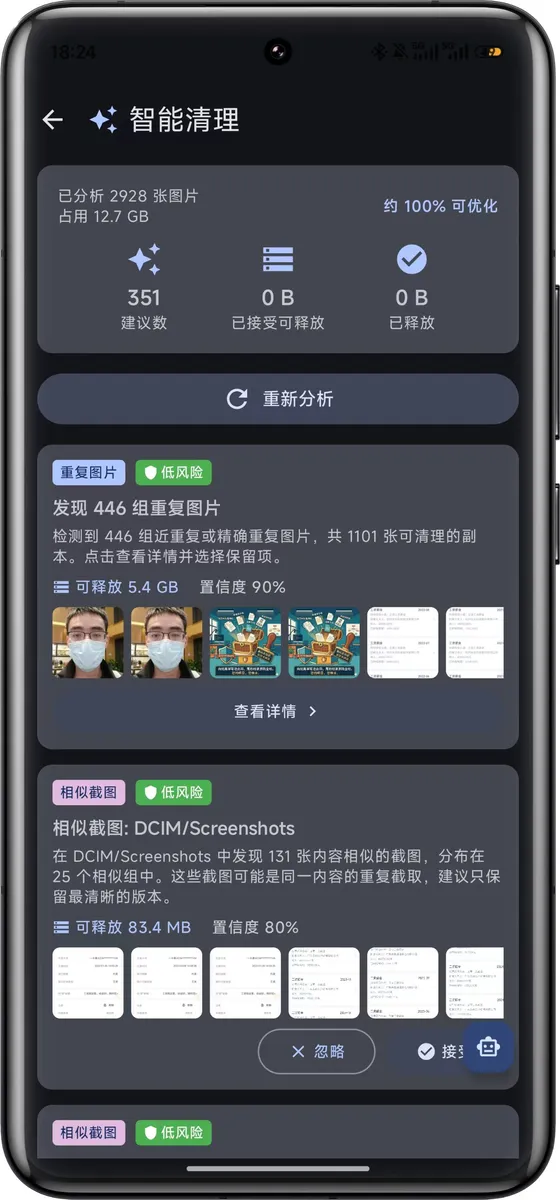
相似图片检测——基于向量距离做近重复分组,不是简单的 hash 比对,能识别截图裁剪、压缩后的"几乎一样"的图。
放几张截图感受下:
 |
 |
 |
 |
完整演示视频(功能比较多):B 站链接
官网:
- 素流 PureFlow
下载:
- Google Play
- 国内直接下载
想问问各位 V 友:
- 你们现在用什么文件管理器?还是直接用系统自带的?
- "用自然语言管理文件"这个需求,你们觉得是真需求还是伪需求?
独立开发,一个人撸的,欢迎使用和反馈。