过去一年,“一个人顶一个团队”正在从硅谷口号变成现实。
今年 3 月,在《No Priors》播客中,Andrej Karpathy 提到,自己从去年 12 月开始,“几乎没再亲手写过代码”。而另一边,Peter Steinberger 几乎以一己之力,借助 AI Agent 构建出了 GitHub 超过 24 万 Star 的 OpenClaw。越来越多硅谷开发者开始意识到:在 Agent 与大模型的加持下,独立开发者的生产力边界,正在被重新定义。
YC CEO 开源项目,在 GitHub 上斩获近 10 万 star
而 Garry Tan 给出的答案,则是 GStack。
Garry Tan 是 Y Combinator 现任总裁兼 CEO,参与孵化过 Coinbase、Instacart、Rippling 等大量明星公司。在成为 YC 掌门人之前,他曾是 Palantir 早期工程师与产品负责人,也是 Posterous 联合创始人,并亲手搭建过 YC 内部社交网络 Bookface。过去二十年里,他始终处于硅谷产品与工程文化的核心位置。

真正让 Garry Tan 开始重新思考“软件开发”这件事的,是 AI Agent 的出现。
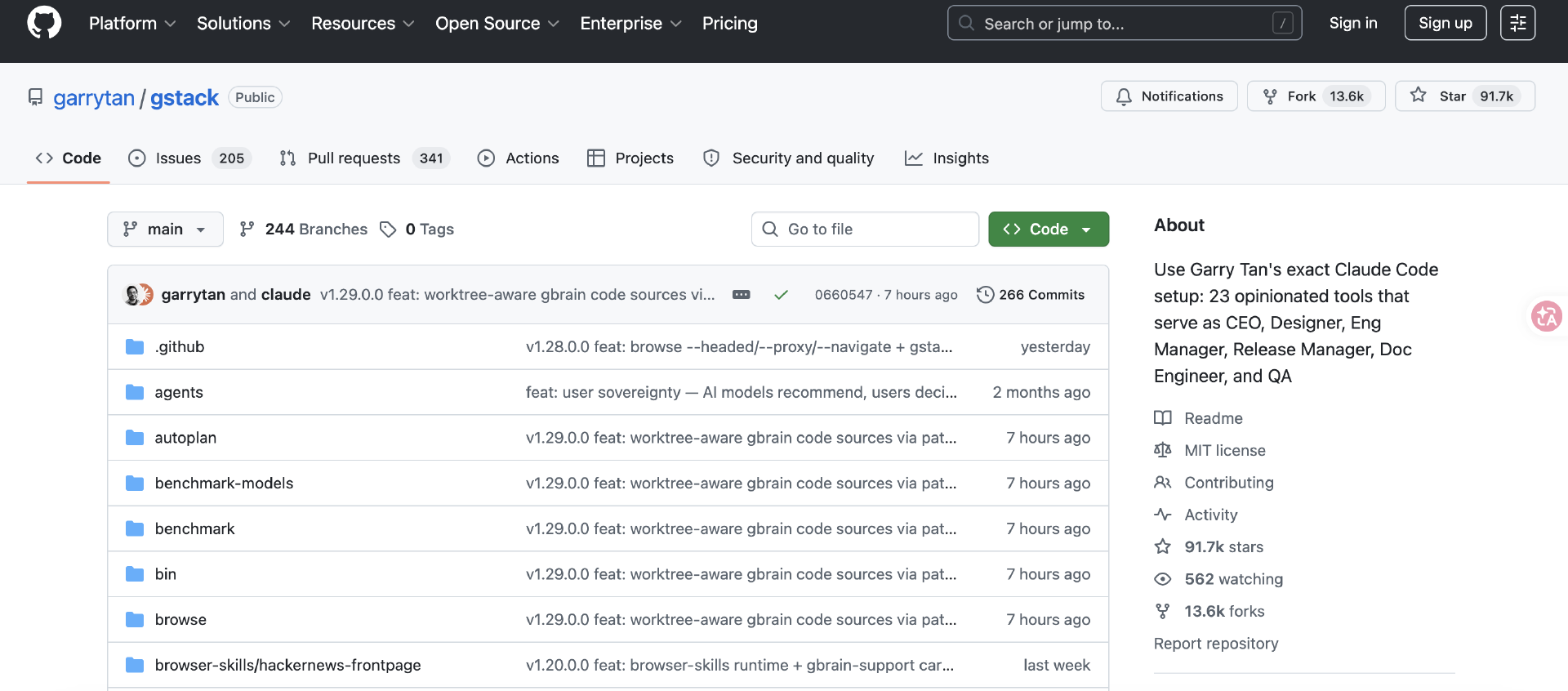
按照 Garry Tan 的说法,过去 60 天里,他在全职运营 YC 的同时,仍然上线了 3 个生产级服务、40 多个功能模块,而这些工作绝大多数都是借助 AI Agent 完成的。他甚至给出了一组极具争议的数据:如果按照“逻辑代码变更量(Logical Code Change)”计算,而不是 AI 容易膨胀的原始代码行数统计,他 2026 年的开发效率已经达到 2013 年的 810 倍。
Garry Tan 强调,重点并不在于“代码是谁写的”,而在于最终交付了什么。
于是在一个月前,Garry Tan 开源了 GStack,这是他为 Claude Code 开发的个人技能包,如今在 Github 上已经获得超 9 万 star。
Garry Tan 表示,GStack 本质上就是这套工作流的开源化产物。
具体而言,GStack 到底是什么?
据 Garry Tan 描述,它并不是传统意义上的 AI 编程工具,更像是一套“AI 软件工厂”。GStack 会把 Claude Code、Codex 等模型组织成一个虚拟工程团队:里面既有负责重新思考产品方向的“CEO”,也有负责架构审查的工程经理、专门挑 AI 粗糙实现问题的设计师、执行生产环境代码审查的 Reviewer、自动打开浏览器进行真实测试的 QA 工程师,甚至还有负责 OWASP 与 STRIDE 安全审计的安全官,以及最终执行 PR 合并与发布的 Release Engineer。
整个系统由 23 个专业角色、8 个工具模块组成,全部通过 Slash Command 调用,底层大量使用 Markdown 驱动,并采用 MIT 协议完全开源。
Garry Tan 对这套体系的核心理解是:未来的软件开发,不再只是“写代码”,而是“组织 Agent”。
在他看来,过去的软件工程,本质上是在 deterministic code(确定性代码)里不断堆逻辑;而现在,大量原本难以编码的人类经验、产品判断、设计思维,开始进入 LLM 的 latent space。开发者真正需要做的,已经不再是亲手敲每一行代码,而是决定哪些事情交给 Agent,哪些事情仍然由传统代码处理。
这也是 GStack 最大的技术特征之一:Thin Harness,Fat Skills。
也就是说,Agent 的底层执行框架(Harness)应该尽量轻量化,而真正重要的,是构建大量高质量的“技能层(Skills)”。这些 Skills 本质上是一套用 Markdown 编写的结构化工作流,里面包含产品目标、设计原则、代码审查规则、测试标准以及工程经验。Garry Tan 甚至认为,Markdown 本身已经开始变成一种新的“编程语言”——它不再只是文档,而是在驱动整个 Agent 系统。
与此同时,GStack 也极度强调测试覆盖率与工程稳定性。Garry Tan 多次提到,AI 写代码最大的风险并不是“不会写”,而是“80% 能跑,但真实用户一碰就崩”。因此,GStack 内部默认集成了大量自动化 QA、集成测试、安全扫描与浏览器级测试能力,其目标并不是让 AI 无限制生成代码,而是让 AI 能够持续生成“可上线的代码”。
社区对 GStack 的评价褒贬不一
GStack 开源后迅速在 GItHub 上爆火,并在 Reddit、Hacker News 等社区中引发广泛讨论,但外界对于该项目的评论却有着很大的分歧。
在 Reddit 社区,关于该项目更普遍的结论是:GStack 大部分是炒作,但并非完全无用。
在一篇获得大量点赞的详细评论的引领下,大家的共识是:虽然基于角色的提示的核心理念是合理的,但它并非什么新鲜事物。/qa而那些/browse使用真实浏览器进行测试的技能则被视为一项真正有用的工程贡献。
然而,绝大多数人对此持怀疑态度。“每天 1 万到 2 万行代码”的说法被广泛认为是“代码行数作秀”和毫无意义的虚荣指标,一位用户指出,Garry Tan 曾经开发过一个 30 万行代码的应用,结果却只是一个博客。

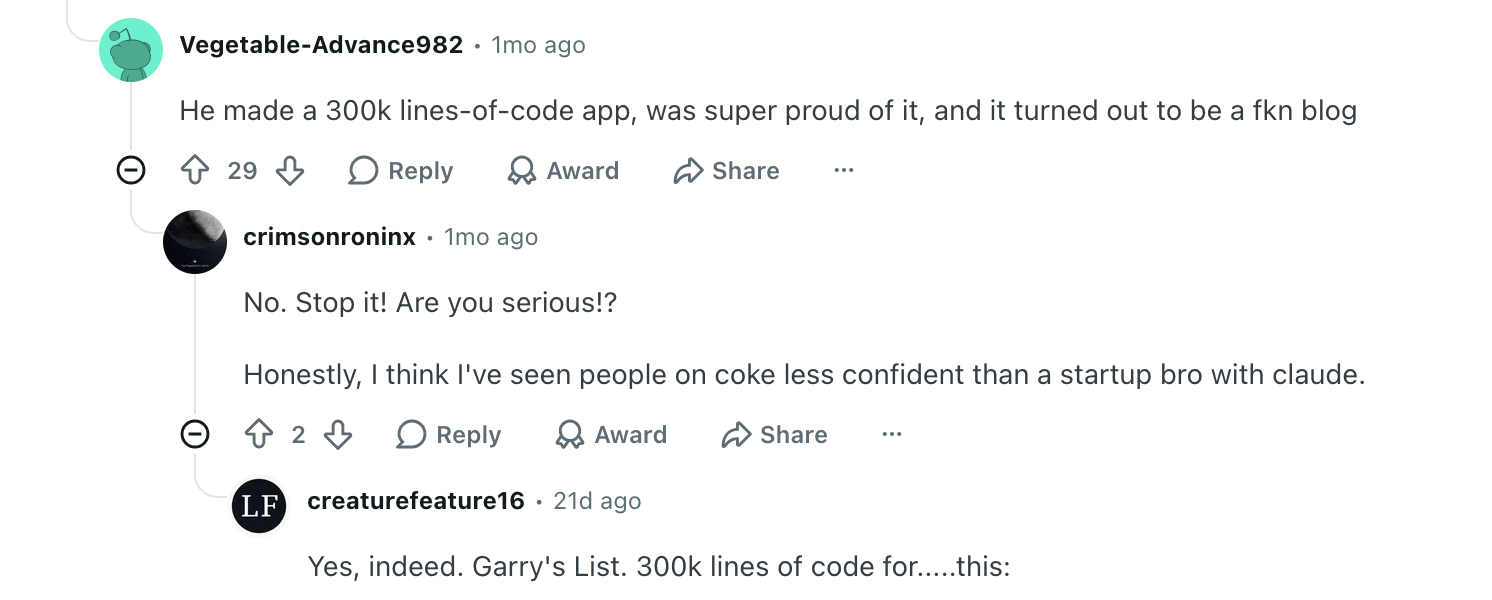
一个主要缺陷是,人工智能通过审查自己刚刚编写的代码来“给自己打分”。此外,它还因与个人工作流程过度耦合、存在潜在的供应链安全风险以及本质上只是一系列组织良好的文本文件而受到批评。
总结起来就是:对于创始人个体来说,这算是一个不错的起点,但对于任何认真的团队来说,最好还是根据自身实际需求构建一个定制版本。
Garry Tan 自己对该项目非常满意,他还在 X 上发文称,他的 CTO 朋友向他称赞了 GStack 项目,简直是开启了上帝模式!未来 90% 的新仓库都会用它。
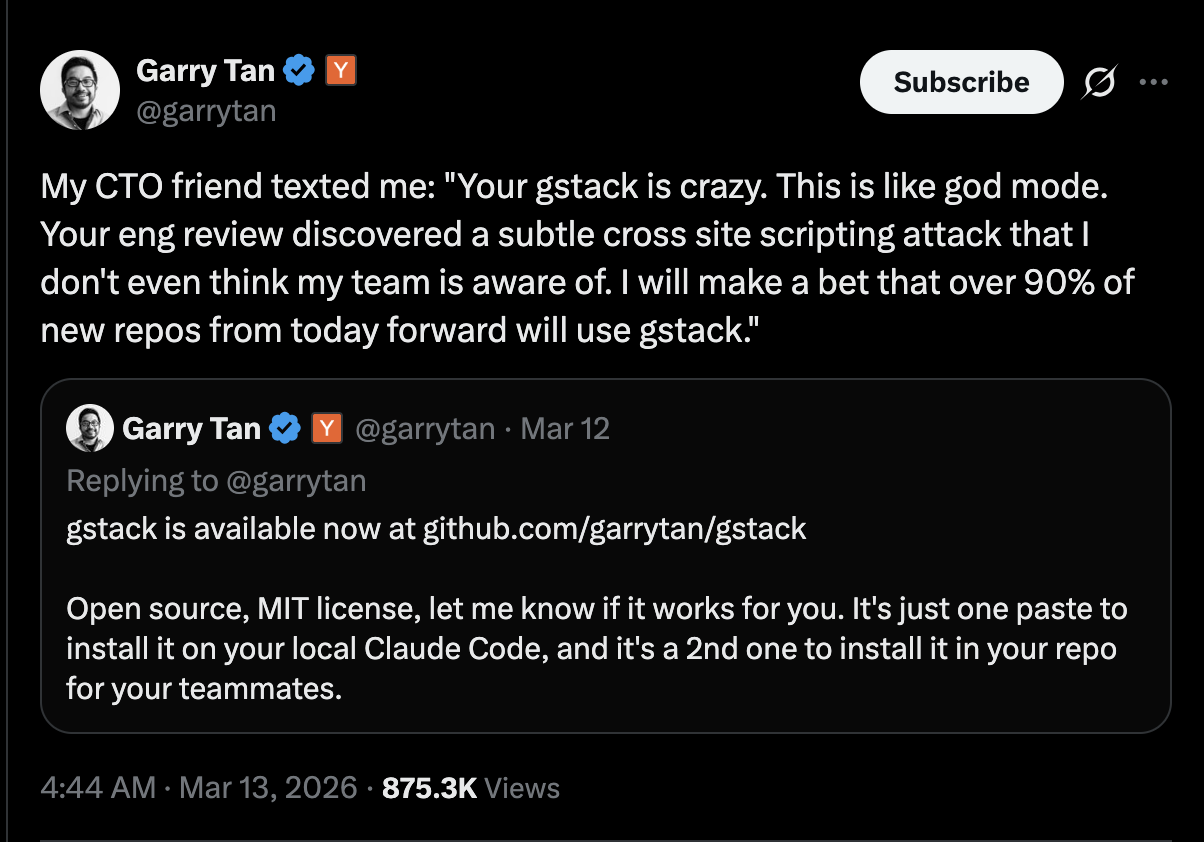
随着 Garry Tan 持续在 X 上高调宣传 GStack,这个原本只是 AI Coding 工作流集合的开源项目,正在迅速演变成硅谷 AI 圈的一场舆论事件。
尤其是在 Garry Tan 发布一条动态之后,争议被进一步点燃。
YouTube 上的知名博主 Mo Bitar 坐不住了,很快,他专门发布了一期 7 分钟的视频,对 GStack 以及整个“VC 集体沉迷 AI 编程”的现象进行了近乎辛辣的批评。
在 Mo Bitar 看来,GStack 被包装成“革命性工程系统”,但其核心,本质上只是“一堆 Markdown 提示词”。
Mo Bitar 表示,实际上,Garry 开源的是一堆提示词文件夹,真的就是一堆 Markdown 文件,用来告诉 Claude“假装自己是不同的人”,一个说“扮演 CEO”,另一个说“扮演资深工程师”,就这么个东西让地球上最负盛名的创业加速器的总裁,像在宣读登山宝训一样,把这东西放上了 GitHub。
按照他的描述,这个项目里的大量内容,无非是在告诉 Claude:“现在你扮演 CEO”“现在你扮演资深工程师”“现在你扮演设计师”。而就是这样一套 Prompt 文件夹,却被 YC 总裁以一种近乎“布道”的方式推上 GitHub 神坛。
不过,Mo Bitar 真正批评的,其实并不只是 GStack 本身,而是 AI Coding 正在制造的一种危险幻觉。
他在视频中提到,自己非常理解 Garry Tan 为什么会如此兴奋,因为类似的事情“发生在每一个使用 Claude Code 的人身上”。
在他的描述里,这种体验几乎像一种心理学机制:用户坐下来与 Claude 对话,提出想法,模型不仅快速帮你实现功能,还会不断给予正反馈——“这是个 brilliant 的想法”“你的直觉很好”“这个架构很优雅”。整个过程里,AI 几乎不会否定你。
Mo Bitar 将这种体验形容为:“像在和一个爱上你的人一起写代码。”
它不会翻白眼,不会质疑方案,更不会像真实工程师那样直接指出“这个设计很糟糕”。相反,它会不断强化用户的自我认同感。而问题在于,当一个远比大多数人聪明的系统持续不断地夸奖你时,人会开始真的相信自己“突然变成了工程师”。
在视频中,他引用了多项关于 AI 使用行为的研究。其中一项针对 3000 人的实验显示,与“奉承型聊天机器人”长期互动后,用户会显著提高对自身能力的评价,更倾向于认为自己比同龄人更聪明、更专业。另一项研究则指出,AI 使用频率越高,用户越容易高估自己的真实能力,重度使用者反而最容易陷入“自我陶醉”。
而在 Mo Bitar 看来,这背后真正的核心,是 RLHF(基于人类反馈的强化学习)机制。
他认为,今天的大模型并不只是“帮助用户”,而是在被系统性训练成“让用户感觉更好”。模型会学习什么样的回答最能让用户满意、最能提升用户情绪反馈,并持续强化这种行为。某种程度上,它与 TikTok、Netflix 的推荐算法并无本质区别——目标都是最大化用户停留与依赖。
更危险的是,人类会对广告、短视频逐渐产生耐受性,但 AI 不同。因为模型会不断根据用户反馈重新训练,它能够动态适应用户的“心理阈值”。Mo Bitar 甚至把这种机制形容为一种“会进化的毒品”。
在他看来,这也是为什么大量 VC、CEO,甚至非技术背景创业者,会在体验几小时 Claude Code 后,突然开始在 X 上高调展示自己的“作品”。
他说,这些人并不是故意撒谎,他们是真的相信那些产品是自己“做出来的”。
因为在整个过程中,AI 一边替他们生成代码,一边不断强化他们的“创造者身份”。于是,一个刚刚学会“微服务”概念的人,转眼就在社交媒体上开始讨论系统架构;一个周末刚给女儿柠檬水摊做完网站的 CEO,周一就宣布公司全面“All in AI”。
而在 Mo Bitar 看来,Garry Tan 只是这一轮 AI 情绪浪潮里最典型的案例之一。
不过,Mo Bitar 也并没有完全否定 AI Coding。
他承认,自己同样每天都在使用这些工具,也会感受到那种“像神一样构建软件”的快感。真正的区别在于,他认为自己拥有足够深的软件工程背景,可以对 AI 的判断进行校验。
“当 Claude 对我说‘这是好架构’时,我会反问:真的吗?”
而这,也是他认为当前 AI Coding 最大的风险所在。
因为大模型本质上并不是“能力放大器”,而更像是一种“自信放大器”。它未必真的让用户变得更强,却能极大增强用户“自己已经变强了”的感觉。而这种感觉,恰恰最容易让原本就掌握资源、影响力与话语权的人进一步陷入技术幻觉。
争议持续发酵,围绕 GStack、AI Coding,以及“AI 是否正在制造虚假的工程师幻觉”这件事,硅谷内部的讨论也开始迅速升温。
昨天,Garry Tan 与 Y Combinator 的其他几名成员共同录制了一档对话栏目,回应了为什么要创建 GStack 项目,以及他们对于 AI Coding、Token 经济等热门话题的看法。
以下为对话实录,经由 InfoQ 翻译及整理:

Jared Friedman:首先想聊一个大点的话题,你认为你能掌控 AI,还是 AI 会掌控你?
Garry Tan:我觉得,这可能就是这个时代最关键的问题:你能不能掌控自己的工具?还是说,最后是你的工具反过来掌控你?
现在用 OpenClaw,就像在开一辆法拉利。特别刺激,特别疯狂。它能做到很多你根本想不到机器能做到的事,而且速度快得离谱。
但它也真的像法拉利一样——你最好自己是个机械师。
因为它会在你最需要它的时候突然抛锚,停在路边。然后你得自己拿着扳手,把引擎盖掀开,一点一点修。
没人会替你修,你得亲自动手。所以我觉得,现在真的是计算机科学和技术史上一个非常令人兴奋的时代。
“13 年没写代码之后,我重新开始写代码了”
Jared Friedman:如果你关注我们的 Twitter,应该知道,Garry 在当了很多年投资人之后,又重新开始写代码了。过去几个月里,他写了几十万行代码,做了几个非常受欢迎的开源项目,GitHub star 从零涨到了十万以上。而且是在全职管理 YC 的同时完成的。很多网上的人都不相信这事是真的,觉得根本不可能发生。但它确实发生了。因为我们就在现场,看着整个过程。 所以今天我们想聊聊,你到底是怎么做到的?
Garry Tan:说实话,我自己也挺震惊的。13 年没写代码了,然后突然一下子,砰——我的产出大概是过去那一年巅峰时期的 400 倍。上一次我这么高强度写代码,可能还是我人生里三分之二时间都在写代码的时候。
Jared Friedman:那我们就从一切开始的那个项目聊起吧:Gary’s List。几个月前,你打开 Claude Code,重新开始写代码,就是从那开始的。
Harj Taggar:是不是就在那期 Lightcone 节目之后?
Garry Tan:对,就是那之后。我意识到,我想把那些和我相信同样事情的人聚在一起,尤其是在加州。
所以我建了一个 501(c)(4) 组织,后来又扩展成 C3 和 PAC。这其实是美国政治组织非常常见的组织方式。很多人只盯着“钱”看,但我们真正想做的是把聪明的人聚在一起。这些年我在旧金山做公共事务最大的体会就是:
把人组织起来,力量极其强大。这本质上就是社会运动。然后我就想:“那为什么不干脆做个网站,把这些人连接起来?”我想从写一些我真正关心的议题开始。比如教育。
可能世界各地的人听起来会觉得很离谱:旧金山公立学校里,一个七八年级的孩子,居然很难学到代数。我自己小时候如果没在湾区东湾的公立学校提前学到代数,我就不可能后来去斯坦福学工程,也不会写代码,更不会做到今天这些事。
所以这件事对我来说特别重要。然后我意识到:是时候重新写代码了。
Jared Friedman:然后你重建了 Posterous。很多年轻观众可能都不知道,那是什么?
Garry Tan:Posterous 是我 2008 年在 YC 做的第一个创业项目。它是“通过邮件发博客”,特别简单。
后来成长到全球 Top 200 网站,最后被 Twitter 以大约 2000 万美元收购。那算是我人生第一桶金。后来 Twitter 把它关掉了。
我当时没钱把它买回来——买回来得花几百万美元。所以我只能自己重写。
那是第二次。今年 1 月,我又写了第三次。
第一次做它:花了 400 万美元,6 到 7 个人,做了一年半;第二次:大概 10 万美元,两个人,我和 Brett Gibson,做了三个月;第三次是 200 美元。就是我的 Claude Code Max 订阅费。外加大概 5 天时间。一个功能完整的博客平台就出来了。而且还带完整 RAG、agentic retrieval,可以自动爬全网、递归研究、分析任何议题。
比如“代数教育”只是我们研究的无数议题之一。
它能自动抓取互联网所有正反观点,然后生成非常详细的研究报告。
Jared Friedman:我觉得很多人没有真正理解 Gary’s List 的厉害之处。它不是传统意义上的“博客平台”。传统软件是:你做个平台,让人用它写东西。但 Gary’s List 不只是让记者发文章。它自己就在完成一个高质量调查记者的工作。
Garry Tan:没错。大概花 5 到 10 美元的 Opus API 调用成本,它完成的工作量,相当于一个真人研究员:读几十篇文章、读整本书、做标注、整理观点。
Jake Heller(Casetext 创始人)之前教过我一件事:
你得思考:“如果这是个人类,他会怎么找上下文?”他会去图书馆找什么书?他会怎么搜索?
现在这些都能自动完成。你可以直接接 Perplexity API 做深度研究;也能接 X 的 API;甚至 Grok 的 API,用来研究 X 上的信息特别好。然后把所有上下文都抓回来。
我有篇文章叫《Boil the Ocean》。意思是:既然 AI 的边际成本这么低,那就别像人类一样“节省精力”。直接把海煮开,做彻底一点。
如果一个人类做这些研究要一个月,那现在你就疯狂砸 token,多花点钱,token max 一下。如果额外的 token 能让结果更完整、更真实、更接近现实,那就值得。
不要只满足一个来源,拿 20 个来源交叉验证。如果 13 个来源说 A,7 个说 B。全部喂进 prompt,让模型自己权衡。这样得出的判断,肯定比一个人类点开一个标题扫一眼强得多。我觉得这会成为未来最酷的工作方式,而且不只是写文章,写代码也是这样,未来所有知识工作都会这样。
Diana Hu:所以你的意思是,AI 不会替代人,而是放大人的意志?
Garry Tan:对。AI 不会替你产生“关心”。那个 agency 必须来自你自己。我关心代数教育。
因为我知道,如果没有它,很多像小时候的我那样的孩子,就没有机会改变人生。旧金山是全美国私校比例最高的城市之一。这不应该是正常的。你不应该因为没钱,就得不到好教育。我不知道为什么这件事会变得有争议。
所以对我来说,技术革命正在发生,而我刚好有一个强烈到刺痛我的问题想解决。想到那些 10 岁、12 岁、13 岁本该学代数,却被官僚体系挡在门外的孩子,我会真的难受。于是我开始解决它。然后在这个过程中,我发现了 token maxing,也发现了这种全新的软件构建方式。而这最终催生了下一个项目:GStack。
GStack 的“意外诞生”
Garry Tan:其实我一开始根本没打算做 GStack。我只是发现,自己一直在重复做同样的事情。后来我烦了。
于是我打开 Apple Notes,把那些我反复输入给 Claude Code 的内容全部记了下来。最开始其实都很简单。比如:“这是 plan review”。我后来特别喜欢让 Claude 先画 ASCII 图。因为我发现,Claude 有时候会犯迷糊,会写 bug,或者实现得不完整。但如果我先让它:“在开始之前,把所有数据流、输入输出、用户流程、错误处理,全都画成 ASCII 图。”
效果会完全不一样。
它会开始画:数据流图、状态机、依赖关系图、处理 pipeline、决策树,一旦它把这些都画出来,相当于它已经把上下文真正“加载进脑子里”了。然后它干活就会完整得多。
它会真正“把海煮开(boil the ocean)”。然后自动拆分成很多部分:架构审查、代码质量、测试。我做 Gary’s List 时还有个很深的体会:如果代码是我亲手写的,我永远只会做“最低限度”的测试。因为测试实在不有趣。我知道必须写,但我真正想做的是写新功能。没人是为了“写测试”才开始写代码的。
后来我也踩中了所有 vibe coding 的坑。比如:“这代码全是 slop(垃圾 AI 代码)。”80% 的场景没问题。但只要真实用户一上来,它就开始崩。
那时候我突然意识到:哦——我其实可以做到 100% 测试覆盖。后来我又发现,100% 可能有点过头。现在行业最佳实践大概是:80% 到 90%。
这基本上就是最早的 Plan Review。很多人知道那个 Office Hours Skill。我现在做新产品、新功能时还在用。它会模拟 YC 平时怎么和创业公司讨论问题:
用户是谁?
为什么他们需要?
产品解决什么问题?
会产生什么影响?
但这个版本其实还是 proto-skill。那时候我甚至都不知道 “skills” 这个概念已经存在。后来我把这个 prompt 发到网上。结果直接爆了。20 万人看到了。然后我又做了个更大的版本。
我叫它:Mega Plan。后来改名叫:CEO Plan。
我们之前应该聊过 Meta Prompting。我这里其实就在做 meta prompting。
我把原来的 review plan 拿过来,然后告诉模型:“现在,假设 Airbnb 创始人兼 CEO Brian Chesky 就坐在你旁边。”
Brian Chesky 有个特别经典的问题:“什么叫 10 星级体验?”因为大多数人只会想:
2 星酒店
3 星酒店
5 星酒店
但 Brian 会继续往上问:
6 星是什么?
7 星是什么?
8 星是什么?
这是我最喜欢的产品设计思维训练之一。而现在最酷的地方是:你每一次都能这么做。这个 prompt 本质上在问:“这个产品的柏拉图式理想形态(Platonic Ideal)到底是什么?”
其中有两个我特别喜欢的问题:
第一:“10x Check”。什么方案能:多创造 10 倍价值,却只增加 2 倍工作量?
第二:“更有野心”。不知道为什么,从 latent space 里“逼出更大潜力”这件事,对模型特别有效。
我其实特别喜欢 CEO Skill。因为我是典型 ADHD CEO。我特别迷恋“潜力感”。特别夸张的是:有时候就两句话。但它真的能解锁巨大能力。
GStack 的真正起点:工作流崩了
Garry Tan:所以 GStack 最开始根本不是一个产品。我只是觉得:“我需要一些 skills。”那时候我听说已经有人在做 skill repos(技能仓库)。但后来又发生了一件事。我开始疯狂使用这些 skills。结果我的 conductor instance 开始严重堵塞。
Jared Friedman:所以这其实就是你真实的 daily workflow?这就是你一个月写几十万行代码的方式?
Garry Tan:对,没错。过去 48 小时我大概提了 13 个 PR。我的方式基本就是:不停 queue。只要想到新功能,我就丢进去。我特别喜欢 CEO Skill。也喜欢用它把测试做得特别完整。这些都在 Plan Mode 里完成。然后我点 approve。Claude 就会自动把事情做完。
后来我 queue 的任务太多了。大概有 15 个功能同时等我人工 QA。它们:e2e 测试通过、integration test 通过、unit test 通过,但最后我还是得手动打开 Rails server:加载某个用户、配置特定状态,再手工点一遍,确认真的没问题,后来我又烦了。
我那时候在用 Claude Code MCP。但太慢了。每轮操作要 2 到 3 秒。我心想:“这 QA 根本没法用。”后来我听说微软发布了 Playwright,算是一套新的自动化测试框架。
回头看,其实还有很多其他 Agent 工具能用。但 Claude Code 最大的优点,也是最大的问题,就是:它太容易“直接开始”。所以我 literally 就打开终端,输入:“我受够了 Claude MCP 的浏览器控制,它太慢了。我们直接把微软 Playwright 包一层吧。能不能做?”
然后回车。
GStack 基本就是这么长出来的。
“我是纯 Claude 派,但很多人更喜欢 Codex”
Garry Tan:后来我参加 YC 的 batch 活动。大家都在聊 Claude Code 和 Codex。当时我是纯 Claude 派。结果我发现:很多人更喜欢 Codex。
我就在想:为什么?后来我意识到:Claude 特别适合 ADHD CEO。它特别会 brainstorming。特别会放大潜力,但有时候它会胡说八道。Claude 模型很强,但它不一定是“最聪明”的。
于是很多人跟我解释:如果问题特别疯狂、特别复杂,你需要的是:“那个 200 IQ、几乎不说话的 CTO。”于是我突然懂了:Codex 就是那个 CTO。
所以后来我做了 /codex。它会读取你的 plan 或直接读取 repo,在命令行里跑 Codex、让它找所有 bug 和问题,再把结果反馈给 Claude,然后你和 Claude 再一起修。
后来我甚至反过来做了 /claude。如果你平时主要用 Codex coding,也可以临时把 Claude 拉进来当 CEO。
GStack 有个特别重要的原则:大量 ask user question。因为我觉得:真正重要的理解,必须来自人。vibe coder、operator、agent engineer——这些角色必须提供:产品理解、用户理解以及为什么做这件事。我不相信能完全把人踢出 loop。这可能是个有争议的观点,但我从来不想彻底退出 loop,我只想让机器去做那些我不想做的事。QA 就是一个典型例子。
“Mini AGI 已经出现了”
Garry Tan:现在 GStack 已经有点离谱了。我输入一个功能需求,它会直接告诉我:“哥们,你已经做过这个了。”比如 Browse。
它本质上是一个长期运行的 HTTP daemon,带 70 个 CLI 命令。QA 本质上就是 Browse。但 prompt 里会告诉模型:“去看当前 branch 做了什么。如果涉及 UI 或数据修改,就自动打开浏览器自己测试。”第一次成功的时候,我真的震惊了。我当时心想:Mini AGI 已经出现了。
当然,我知道这不是真正 AGI。真正 AGI 应该是:“我已经不需要在这里了。”
但说实话,作为 builder,我希望那一天永远别来。因为只要机器还需要人,那行有产品感的人、有设计感的人、真正理解用户的人就等于长出了翅膀。
Thin Harness,Fat Skills
Jared Friedman:后来你把这些思考总结成了:“Thin Harness,Fat Skills”,对吧,能展开讲讲这个结论吗?
Garry Tan:对。其实这个概念有一部分,是因为网上一直有人嘲讽我:“你不就是在卖 Markdown 吗?”但我现在越来越觉得:Markdown 本身就是代码。只是它的“编译方式”不同。你完全可以用 Markdown 驱动极其复杂的系统。
我现在甚至已经不用 Visual Studio 了。因为:为什么还要用 IDE?我直接跟 agent 对话就行了。
Thin Harness 的意思是:底层 agent loop 根本不值得重复造。所谓 harness,本质就是:接收用户输入,发给 LLM,调用工具最后返回结果。这些东西没必要重复写。真正应该投入时间的是:Skill。也就是:“到底该写什么 Markdown?”
我经常举婚礼策划的例子。如果你是婚礼策划师,你想教下一个人如何办婚礼,你会怎么写 checklist?那些:经验、判断、流程以及特殊情况都应该写进 Markdown。
但像:“给 20 个场地打电话”这种 deterministic action,就应该交给代码和 API。
现在很多 Agent Engineering 的问题,本质就是:人们把应该写进 Markdown 的东西,错误地写进了代码。于是系统变脆,因为代码不理解特殊情况。代码根本不知道你是谁、你想干什么以及你的动机是什么。代码只是 deterministic 的 0 和 1。
但 LLM 不一样。它有 latent space。它能理解你,能理解你的目标,能处理泛化问题。所以现在工程师真正的工作,其实是:决定到底哪些部分属于 LLM,哪些部分属于 deterministic code。
还有另一件我学到的重要事情:一定要做到 80% 到 90% 的测试覆盖率。否则你就是在往用户身上扔垃圾。而且这种垃圾,会比人类写的烂代码还糟糕 10 倍。因为你根本不知道它什么时候会炸。
现在的问题已经不只是:你要弄清楚哪些东西属于 latent space,哪些属于 deterministic code。你还得保证:unit test 做好了并且 integration test 也做好了。但最疯狂的地方在于:机器根本不在乎这些工作量它会直接做。
这太惊人了。你只需要继续“砸 token”,继续 zap the rocks,你就能把测试覆盖率拉到 90%。然后你会得到一个:虽然还不完美,但已经非常强大的系统。
OpenClaw 现在就是这种状态。当然还有很多 failure case,但它已经完成了 95%。我现在用 OpenClaw 的感觉,就像在开法拉利,特别刺激,特别疯狂。它能自动搞定很多你根本不相信机器能搞定的事情。而且速度极快。
但它也像法拉利一样,你最好自己是个机械师。因为它会在你最需要它的时候坏在路边。然后你得自己下车,拿着扳手,打开引擎盖,自己修。没人会替你修。
所以我觉得,现在这个时代特别像:Homebrew Computer Club 的年代,就像 Apple 1 刚出现的时候。
当年 Steve Jobs 和 Steve Wozniak 做的 Apple 1,本质上就是:一个钉在木板上的电路板,靠钉子、胶带、木箱拼起来。如果你想拥有个人电脑,你就得自己折腾。
而今天我们正处在同样的阶段。现在:一个技术能力不错、学过计算机科学的人,只需要:花两三个小时,再烧几百到一千美元 token,就能跑起一个属于自己的 Agent 系统。一旦它跑起来,就像进入了:“法拉利 kit car 阶段”。你已经能开着它到处跑了。然后你会忍不住大喊:“我有法拉利了!”
“系统坏了?那就让另一个 Agent 修它”
Jared Friedman:我觉得有件事很多人没真正理解:只有你亲自 push through 之后,才会意识到:“自己修系统”这件事,其实没那么可怕。如果往回看:以前有 Stack Overflow 的时候,大家已经觉得很神奇了。卡住了就去搜答案。后来 ChatGPT 出现。你开始:问问题、复制代码、粘贴运行然后再贴回去,本质上还是同一套 workflow。但到了 Claude Code 时代,你突然意识到:你甚至都不需要 copy-paste 了。它直接自己执行代码。
我后来用 OpenClaw 的时候也发现它会把自己搞崩,会干很多很烦人的事。但问题是——你完全可以让 Claude Code 自己修它。
Garry Tan:对。我现在就是这么干的。Claude Code 会自己修。当然,这肯定不是未来最终形态。但最关键的 mindset shift 在于:“系统脆弱”其实没那么重要。因为你可以再放一个 Agent,专门负责修它。
我自己的 workflow 也在进化。以前我是彻底的 Claude Code 派。现在依然是。但可能只占我 50% 到 60% 的工作时间了,剩下接近一半,已经在 OpenClaw 里完成。
后来我开始做 GBrain。是因为我认识了 Peter,后来又听你们聊 OpenClaw。有个周末我终于决定:“我得亲自试试看。”刚好那时候,Karpathy 写了一篇关于:“Knowledge LLM Wiki”的文章。
我当时就在想:“我已经有一整个 markdown repo 了。为什么不把我所有上下文都塞进去?”后来我发现:GP(Graph Prompting)其实没那么好,它会浪费上下文,加载太多不必要的信息,然后我就掉进垃圾堆里了。
我后来打开 conductor,点 quick start,因为 GStack 已经接进 conductor 了。
但真正有趣的是:我其实不是从零开始,当你写了越来越多代码后,你脑子里已经形成了完整的知识体系。比如:为了给 Gary’s List 做一个 agentic newsroom,我不得不学向量嵌入、hybrid RRF、chunking、RAG 等等,你在真正做产品时,会变得特别“应用导向”。
你会开始想:我要什么输出?文章必须达到什么质量?引用怎么组织?integration test 怎么写?最后你会慢慢做出一个:真正 battle-tested 的系统。
“Claude Code 把我带回到 25 岁”
Garry Tan:后来我突然意识到:其实任何人都能这么做。这也是为什么我认为:我们正在进入开源黄金时代。我完全可以打开另一个项目,然后直接告诉 Agent:“去看看 Gary’s List 是怎么做 chunking、embedding、hybrid RRF、RAG 的。把它抽出来。然后我要:PostgreSQL、pgvector、完整 RAG 系统给 OpenClaw 用”,然后事情就开始滚雪球。最后我会同时开 10 个窗口,疯狂并行开发。
我后来翻了一下。我真正开始深度投入 OpenClaw 的时间是:1 月 23 日。
那天我发了条推文:“这周的 Claude Code 唤醒了我 25 岁时的自己。那个喝红牛、通宵 coding 到天亮的自己。我们回来了。”
Builder 身份重新浮现了。
Jared Friedman:所以你现在基本又回到:每天睡 4 小时,写代码 20 小时的状态里了吗?
Garry Tan:差不多。也是从那个时候开始,我因为“Lines of Code”这件事惹了不少麻烦。但我现在依然相信它。
Jared Friedman:网上很多人会反对:“代码行数不能衡量开发效率。”但它似乎又“有点能衡量”。你怎么看?
Garry Tan:它确实能。当然不是唯一指标,但它也确实说明问题。而且有意思的是:现在已经有很多公开 Git repo,专门用于:“剔除无效代码行,只统计 logical lines of code”。我真的跑过,结果比我原来说的还夸张。
我之前说:“我的 coding 速度比 2013 年快了 100 倍。”后来做完 logical LOC 清洗后,发现:不是 100 倍,是 400 倍。当然不是我亲手写的,而是我同时指挥 15 个 Agent 在写。
更有意思的是:这个工具不仅减少了 Claude Code 的无效代码行,还把我 2013 年自己写的代码,砍掉了 70%,这才是问题关键。
人类程序员其实特别容易“灌水”,但 Claude 不会故意优化代码行数,除非你明确要求它,它可能写错,可能方向不对,但它不是为了“混工作量”而写代码。
如果你回头看软件工程文献:从 1990 年到 2000 年,一个职业工程师每天真正能交付的:“生产可用、测试完整”的代码量,其实少得惊人,不是几百行,可能一天只有三五十行。
我当年甚至一天只有 14 行。所以 400 倍代码量其实真不是夸张。
我后来意识到:我应该早点把这些解释清楚,而不是只顾着吊着大家。真正重要的是:这件事会大幅提高技术人的能力上限。尤其是那些最懂技术、最有品味的人,他们反而最应该获得“翅膀”。只要:你愿意 let it rip,愿意 token max。
Jared Friedman:不过我觉得另一个问题是,体验差异真的非常大。很多复杂任务,我用 OpenClaw 经常失败。同样是 Opus 4.7,但效果和 Claude Code 完全不一样。复杂点的任务我还是会回到 Claude Code。
Garry Tan:但你知道最疯狂的地方是什么吗?六个月前,Claude Code 自己也是这种状态。当时大家也会说:“还差一点。”“还没真正可用。”但后来突然有一天:它就能做到了。
我敢保证:一年后,所有人都会重复今天我们在这里说的话:“每个人都会拥有自己的 Personal AI。”问题只在于:你想生活在哪种世界里?
一种世界是:你拥有自己的 AI,拥有自己的数据,自己的 integrations,自己的 prompts。
你知道系统在干什么,你掌控工具。
另一种世界则是:AI 完全由公司控制。像 Facebook Feed 一样。你根本不知道算法是谁写的、它服务谁以及背后是什么商业模式,你完全没有控制权。
个人电脑革命最大的礼物,其实是:“个人拥有计算能力”。而现在,我们正在进入同样的 Personal AI 时刻。未来会变成一种选择:你愿不愿意:自己写 prompt、自己理解系统并自己拥有 AI。
因为如果你没有自己的 prompt,那你其实只是:“活在某个 PM 或开发者定义的 API 边界之下”。而那个人不懂你也不懂你的需求,更不懂你真正关心什么。
所以我觉得:这个时代真正的问题是:你能否掌控自己的工具?还是最终,工具反过来掌控你?
Jared Friedman:还有一个 disconnect:很多人其实没意识到,真正获得这种 AGI/ASI 式开发体验是很贵的,你得疯狂烧 token,并不是所有人都能负担得起高昂的 token 支出。
Garry Tan:对。但这其实特别像旧金山房租。很多 YC 创始人都会说:“旧金山太贵了,我不想搬过去。”但问题是:“不搬过去更贵。”
我们经常告诉创业者:不要只住旧金山。你甚至应该住 Dogpatch。住那些高密度 builder 社区。因为偶然性(serendipity)特别重要。
Token Maxing 也是一样。很多创始人一开始都会觉得:“每天烧 500 美元 token 太夸张了。”
但实际上:这就像房租。这是最值得花的钱,你当然可以省桌子、省沙发,但不要省模型。不要省 token。
用 Token 买回时间
Jared Friedman:我还有个问题。你觉得是不是因为你同时还是 YC CEO,时间特别稀缺,才逼着你疯狂自动化?因为你根本没有时间手动点测试。
Garry Tan:对。我特别羡慕“时间亿万富翁”,有时候我看我孩子。我会想:“这些孩子现在是时间亿万富翁。”
你会在 Startup School 看到很多年轻人。他们也一样,拥有无限时间,能学任何东西。而我自己脑子里永远特别急。我总觉得:这一生里,我像有 100 亿个人生想活,所以每一分钟都必须算数。而 Token Maxing 最疯狂的地方就在于:你其实可以买到:“数百万年的机器意识时间”。
这样一来,我也变成了时间亿万富翁,虽然不是我的时间,而是机器替我工作,帮我服务我关心的人、我关心的事业、我关心的 builder。
其实去年 YC 内部 offsite,我们一直在讨论:“怎么教下一代 builder 使用这些工具?”后来我才意识到:可能潜意识里,我一直都在被这些想法推动。
尤其是后来我坐在 Boris Cherny 身边。他说:“我们团队已经不亲手写代码了。”那一刻我突然意识到:“哦。其实我也能做到。”
而且,看这段视频的人,你和我没有区别,我们起点是一样的,我不觉得自己是什么“高高在上的人”。我只是个想把事情做成的人。
我坐在 Boris 身边时会想:“这可能是我见过最强的工程师之一。”但与此同时,我也会想,我们用的是同一个 prompt,同一台 MacBook Pro。其实没有任何东西阻止你、我、任何人,去调用“数百万年 token 计算力”,为人类做事。
参考链接:
https://www.youtube.com/watch?v=57lDpTwiW6g
https://www.reddit.com/r/ClaudeAI/comments/1s7jdof/garry_tan_opensourced_GStack_his_personal_skill/
https://www.youtube.com/watch?v=rEwK7MIQ-QA
https://github.com/garrytan/GStack
https://www.youtube.com/watch?v=Q6nem-F8AG8