整理 | 华卫
AI 是否正在结束“回合制”聊天的时代?
所有在工作或日常生活中经常使用 AI 模型的人都知道,在文本、图像、音频和视频等各种模态下,现在基本的交互模式仍然是一样的:人类用户先提供输入,然后等待从几毫秒到几分钟不等(在某些特别复杂的问题中,甚至需要数小时或数天),随后 AI 模型再给出输出。用 Thinking Machines 的话说,目前大多数 AI 模型都是通过“外挂式”的方式来实现交互,将不同组件拼接在一起以模拟打断、多模态或并发等能力。然而,这类手工构建的系统终将被通用能力的进步所超越。
“如果 AI 真正要承担那些需要自然交互的工作,它就必须超越这种「回合制」的交互方式。最终,它需要能够更流畅、更自然地响应人类输入,甚至在处理下一次人类输入(无论是文本还是其他形式)的同时就做出回应。”这是 Thinking Machines 的观点。去年,前 OpenAI 首席技术官 Mira Murati、前 OpenAI 研究员兼联合创始人 John Schulman 等人创立了这家资金充足的 AI 初创公司,致力于让先进 AI 系统“更易理解、更可定制,并具备更通用的能力”。
今天,Thinking Machines 宣布推出“交互模型”TML-Interaction-Small,将其称为“首个同时具备强大智能/指令遵循能力与交互性的模型”。据介绍,这是一个拥有 2760 亿参数的混合专家(MoE)模型,其中活跃参数为 120 亿,可以持续接收音频、视频和文本输入,并在实时中进行思考、响应和行动,不依赖外部“脚手架”来实现交互能力。根据第三方基准测试结果,这种方法在性能上取得了显著提升,同时也降低了延迟。
不过,该模型目前尚未向公众或企业开放,该公司在公告博客中表示:“在接下来的几个月里,我们将开放一个有限的研究预览以收集反馈,并计划在今年晚些时候更广泛发布。”
137 页训练日志的交互模型,实力碾压其他前沿模型
在研究预览中,Thinking Machines 展示了 TML-Interaction-Small 模型在交互能力上的质变,以及在智能与响应速度之间达到的当前最先进的综合表现。
“整体体验更像是在协作,而不是在‘下提示词’。”演示视频中,OpenAI 前应用研究副总裁、Thinking Machines 联合创始人翁荔出镜展示了 TML-Interaction-Small 模型的无缝对话管理能力。该模型能够隐式判断说话者是在思考、让出话语权、自我修正,还是在邀请回应,无需单独的对话管理模块。
视频
在 X 上,翁荔表示,“过去几个月,我们玩得很开心,也有很多压力,最终产出了 12 个版本(外加大量子版本)和 137 页的训练日志。事实证明,人与人之间的协作对于提升人机协作非常重要。”
不仅如此,TML-Interaction-Small 模型还解锁了一系列原本需要通过“外部脚手架”实现的能力,包括:
语言与视觉的即时插话:模型可以根据上下文在需要时主动插入,而不仅仅是在用户说完之后才回应。
同时语音(Simultaneous speech):用户与模型可以同时说话(例如实时翻译)。
时间感知(Time-awareness):模型对时间流逝具有直接的感知能力。
同时进行工具调用、搜索与生成式 UI:在与用户对话(说与听)的同时,模型可以并行执行搜索、浏览网页或生成界面,并将结果自然地融入对话之中。
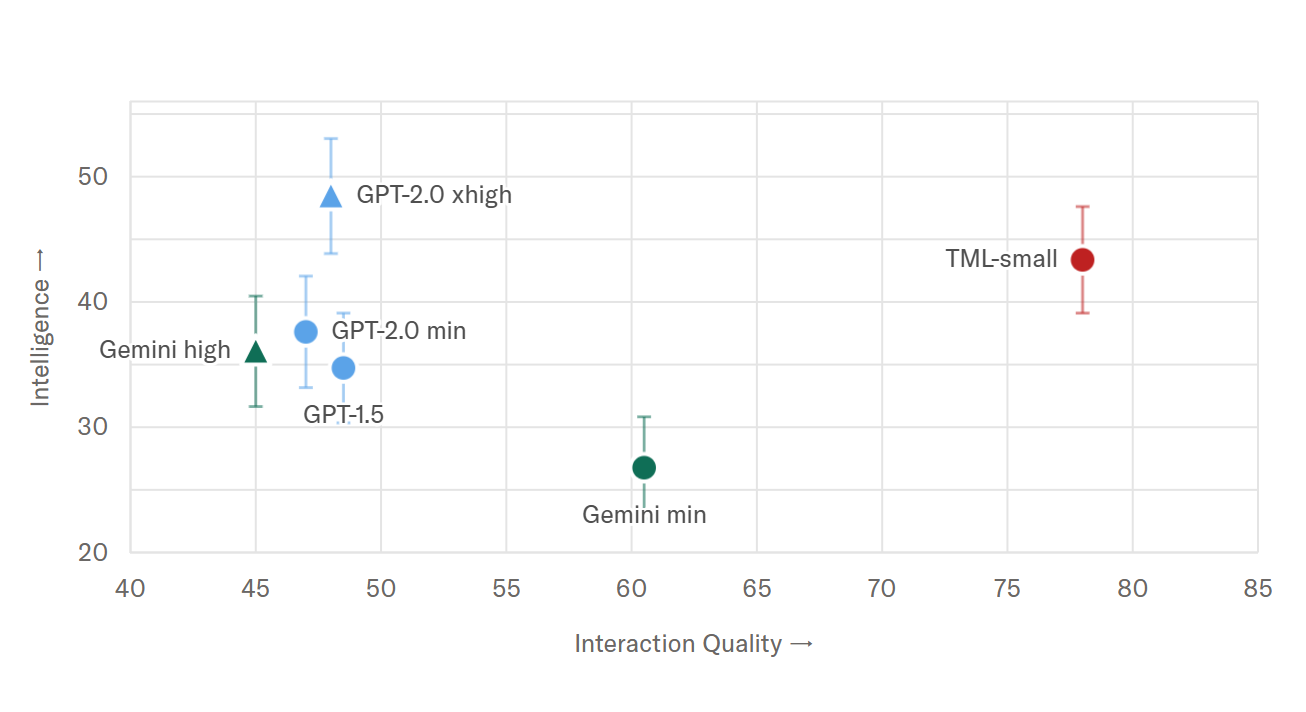
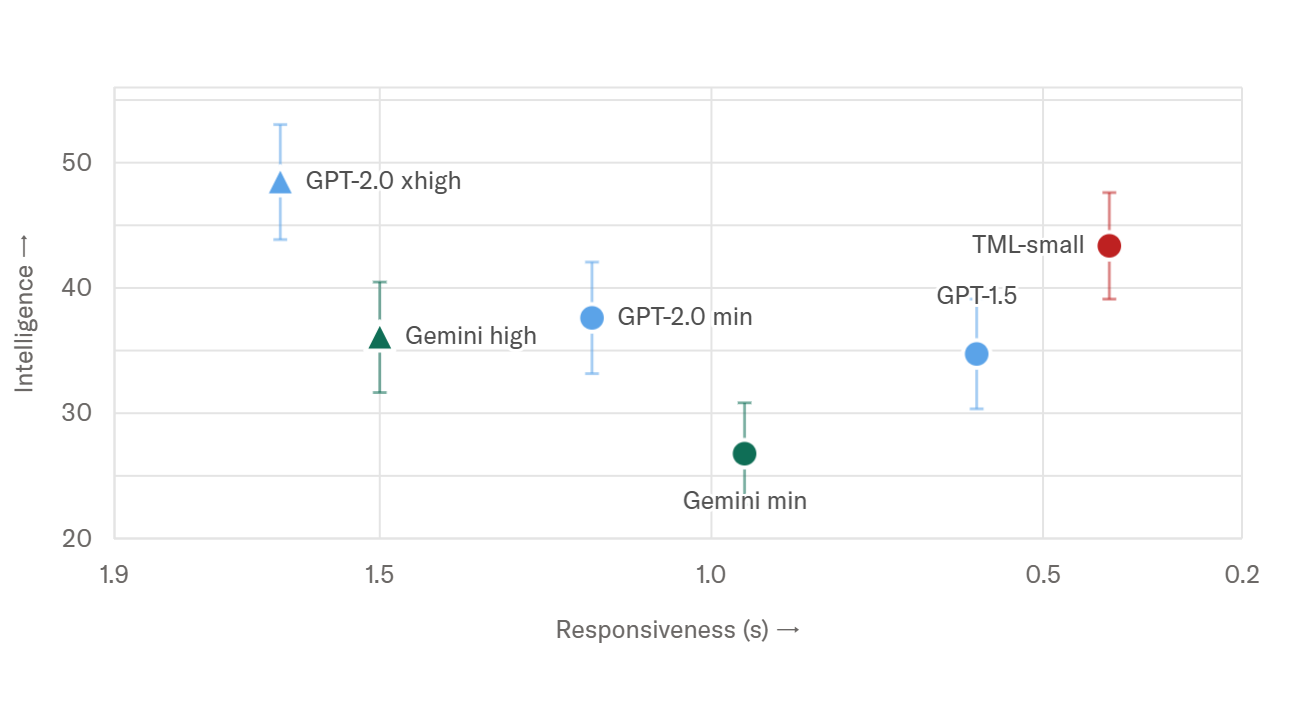
为衡量交互质量,该实验室使用了 FD-bench,这是目前少数专门用于衡量交互性的基准之一。为量化智能水平,他们使用 Audio MultiChallenge,这是一个常用的基准,用于评估智能和指令遵循能力。结果显示,TML-Interaction-Small 显著优于现有的实时系统,包括 Gemini-3.1-flash-live 和 GPT-realtime-2.0 minimal。
响应速度:其轮次响应延迟为 0.40 秒,而 Gemini-3.1-flash-live 为 0.57 秒,GPT-realtime-2.0 minimal 为 1.18 秒。
交互质量:在 FD-bench V1.5 上,其得分为 77.8,几乎是主要竞争对手的两倍(GPT-realtime-2.0 minimal 为 46.8)。在 FD-bench v1.5 中,模型会接收预录音频,并需要在特定时刻作出响应。该基准从多个场景评估模型行为,包括用户打断、用户回应性反馈(backchannel)、与他人对话以及背景语音。
同时,该实验室改造了 RepCount-A、ProactiveVideoQA 和 Charades 三个基准来评估模型的视觉主动性。结果显示,在 RepCount-A(视频中物理动作计数)和 ProactiveVideoQA 等专项测试中,Thinking Machines 的模型能够主动参与视觉环境,而其他前沿模型则保持沉默或给出错误答案,包括高推理模型。
Thinking Machines 认为,通过将“交互性”内化为模型的一部分,模型规模的扩展将不仅让其更聪明,也会让它成为更高效的协作伙伴。此外,他们表示,虽然预计随着模型规模的扩大,交互能力也会进一步提升,但目前更大规模的预训练模型在这一实时交互场景下仍然过于缓慢,无法投入使用。“今年晚些时候,我们计划发布更大规模的模型。”
从零开始训练,200 毫秒为单位实时响应
这次发布的核心,是 AI 在“时间感知”和“存在感”上的一次根本性转变。当前的前沿模型通常以单线程方式体验现实。它们会等待用户完成输入后才开始处理,并且在生成回应时,其“感知”是冻结的。在博客中,Thinking Machines 的研究人员将这种现状描述为一种限制,它迫使人类不得不去“迁就”AI 接口,比如把问题写得像邮件一样,并将思考打包成一整块再输入。
为解决这种“协作瓶颈”,Thinking Machines 从零开始训练了这一交互模型,并放弃了标准的交替式 token 序列。取而代之的是,他们采用了一种多流(multi-stream)、微回合(micro-turn)的设计,可以以 200 毫秒为单位同时处理输入和输出,确保实时响应能力。这种“全双工”(full-duplex)架构使模型能够实时地“听、说、看”,从而在用户说话时进行回应性反馈(backchannel),或在捕捉到视觉线索时主动插话。例如,当用户在代码片段中写出 bug,或者有朋友进入视频画面时。
技术上,该模型采用了无编码器的早期融合(encoder-free early fusion)。系统不再依赖像 Whisper 这样庞大的独立编码器来处理音频,而是通过一个轻量级嵌入层,直接接收原始音频信号(以 dMel 表示)和图像块(40×40),并在 Transformer 架构中从零开始联合训练所有组件。
由于实时交互需要近乎即时的响应速度,而这往往与深度推理能力存在冲突,该实验室因还此设计了一种由两部分组成的系统:
交互模型(Interaction Model):始终与用户保持持续交互,负责对话管理、存在感维持以及即时响应。
后台模型(Background Model):作为一个异步代理,负责处理持续性推理、网页浏览或复杂工具调用,并将结果流式传回交互模型,由后者自然地融入对话中。
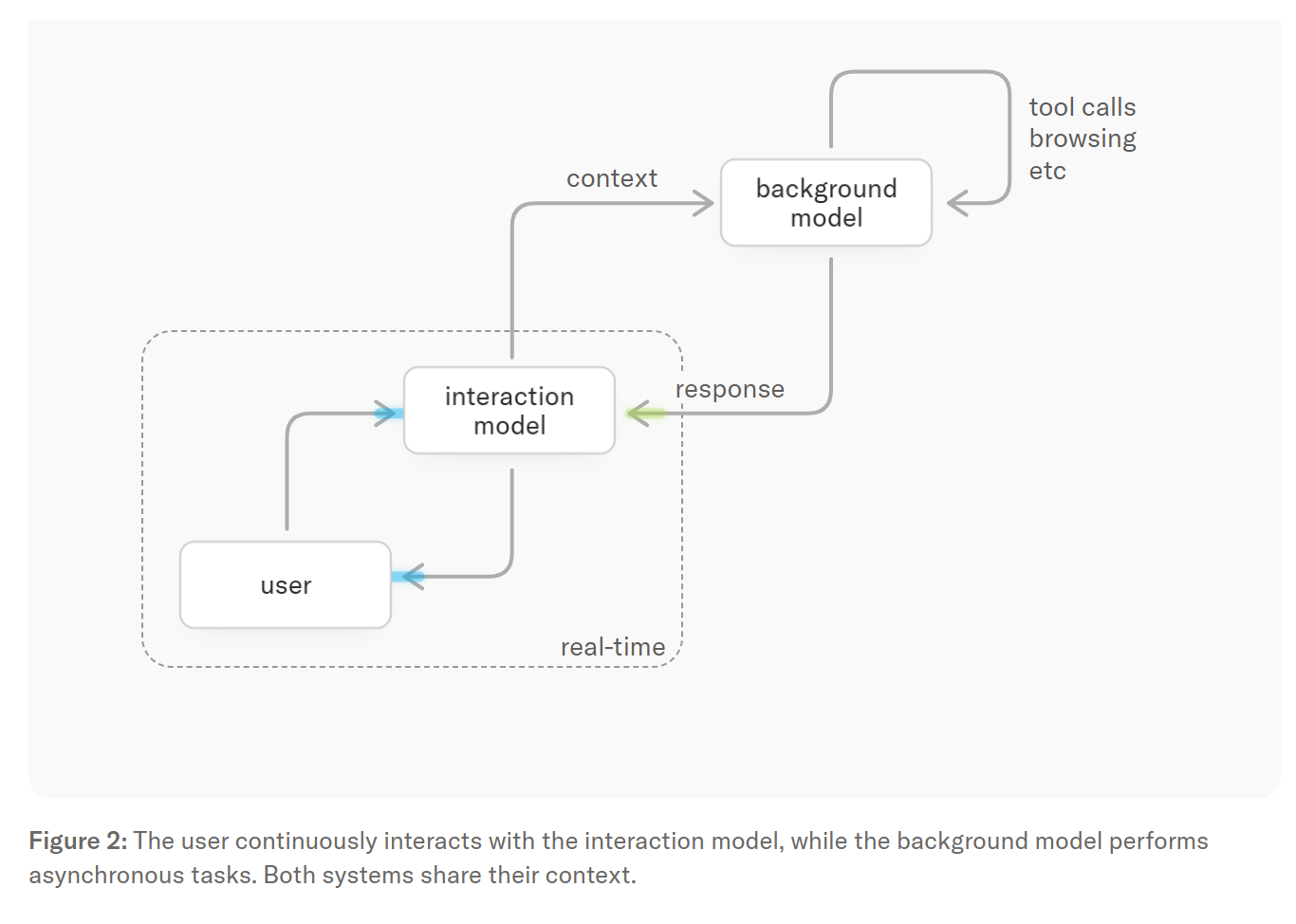
在整个过程中,交互模型始终保持在线,回答后续问题、接收新的输入、维持对话上下文,并在后台结果返回时将其整合进对话中。当某个任务需要比即时响应更深层的推理时,交互模型会将其委托给异步运行的后台模型。这种分工让用户既能获得高响应速度,又能享受到完整的智能能力,包括推理模型的规划能力、工具使用能力以及代理式工作流,同时又具备非“思考型”模型的低延迟响应。
并且,这种架构使 AI 能够在执行任务(如实时翻译或生成 UI 图表)的同时,继续监听用户反馈。这一功能在发布视频中也得到了展示,模型在生成条形图的同时,给出了类似人类反应时间的多种提示反馈。需要注意的是,后台模型和交互模型本身都具备智能能力。即使单独使用,交互模型在交互性能和智能基准测试上也具有很强的竞争力。
一旦开放,将为企业带来巨大价值
如果 Thinking Machines 的交互模型向企业开放,很可能将从根本上改变企业将 AI 融入运营流程的方式。像 TML-Interaction-Small 这样的原生交互模型,可以实现当前标准多模态模型无法做到或极其脆弱的多种企业能力。
当前的企业 AI 必须完成一个“回合”后才能分析数据。而在制造业或实验室环境中,原生交互模型可以持续监控视频流,一旦检测到安全违规或流程偏差,就能主动插入提醒,无需等待工作人员提出问题。该模型在 RepCount-A(精确计数重复动作)和 ProactiveVideoQA(随着视觉证据出现即时回答问题)等视觉基准中的表现,表明它可以作为高风险物理任务的实时审计员。
在语音客服中,主要的摩擦来自于 2026 年标准 API 常见的 1–2 秒“处理延迟”。Thinking Machines 的模型将轮次延迟降低至 0.40 秒,大致相当于自然人类对话的速度。由于其原生支持同时语音处理,企业客服机器人可以在不打断用户的情况下,一边倾听客户情绪,一边提供“回应性反馈”(例如“我明白”“嗯嗯”),并提供实时翻译,使对话更像自然交流,而不是一段段割裂的录音。
标准大模型缺乏“内在时钟”,只有在文本提示中提供时间信息时才“知道时间”。而交互模型天生具备时间感知能力,可以管理时间敏感流程,例如“每 4 分钟提醒我检查一次温度”或“如果这个流程比上一次耗时更长就提醒我”。这对于工业维护和制药研究尤为关键,因为时间是核心变量。
此前,Thinking Machines 表示,将在其发布中坚持“重要的开源组件”,以赋能研究社区。但目前,尚不清楚这些新的交互模型是否会遵循同样的开源策略。
另值得一提的是,此次模型发布前,Meta 已从 Thinking Machines 挖走 7 名创始成员。据外媒报道,挖人前,Meta CEO 马克·扎克伯格曾接触 Mira Murati,试图收购 Thinking Machines Lab,但被拒绝了。
不过,Thinking Machines 并非单向流失人才,公司也聘请了 PyTorch 创始人 Soumith Chintala 担任 CTO,并引入 Neal Wu 等知名技术人才。有外媒报道称,曾在 Meta 工作 8 年、负责多模态感知系统的 Weiyao Wang 也已加入该公司。目前,该公司的规模增长至约 130 人。
参考链接:
https://thinkingmachines.ai/blog/interaction-models/