要点速览
我们重新设计了 ClickHouse 全文索引 (full-text index),使其能够在对象存储 (object storage) 上高效运行。
新的布局 (layout) 倾向于顺序访问 (sequential access),并且无需读取被索引的文本列,即可直接从索引中响应大量查询。
本文将深入探讨这一新设计,内容由负责构建该设计的工程师们撰写。
重新思考对象存储的全文搜索
ClickHouse 中的全文搜索 (full-text search) 经历了多次迭代,旨在将快速、原生的文本索引能力引入 列式分析数据库 (columnar analytical database)。每一次迭代都显著提升了其性能、可用性以及与 查询引擎 (query engine) 的集成度。
然而,随着 ClickHouse Cloud 的引入,一个新的制约因素浮现。
即使数据存储在对象存储上而非 本地磁盘,文本索引也必须提供同样卓越的性能。
远程对象存储上的数据读写与本地存储相比,其性能特性存在根本性差异。那些依赖随机读取 (random reads) 或频繁查找少量字节的设计,在规模化应用时极易成为性能瓶颈。鉴于这些制约,我们重新设计了新的文本索引。
在本文中,我们将首先深入探讨新文本索引的内部设计,以及查询引擎在执行全文搜索时如何利用它。文章的后半部分将从实现细节转向配置和使用。
如需了解 ClickHouse 全文搜索的高层概览及其适用场景,请参阅我们的正式发布公告(https://clickhouse.com/blog/full-text-search-ga-release)。
新文本索引的设计
正如我们早期关于 ClickHouse Cloud 缓存工作的讨论中所述,当数据驻留在远程对象存储上时,实际的性能瓶颈是延迟 (latency) 而非带宽 (bandwidth)。
对象存储提供了高吞吐量,但其访问延迟显著高于本地磁盘。
之前的文本索引依赖于分散查找模式 (scattered lookup patterns),尽管这种模式在本地磁盘上效率很高,但由于大量小规模、不连续的查找操作会放大延迟,因此在对象存储上变得十分缓慢。
为了在对象存储上保持高性能,我们重新设计了文本索引,使其倾向于 顺序访问模式 (sequential access patterns)。这样既能高效利用对象存储,又不会降低本地磁盘上全文搜索的性能。
为了理解其实现方式,我们接下来将详细介绍所有相关的索引数据结构,首先从索引在磁盘上的存储方式讲起。
提醒一下,ClickHouse 将表数据以数据分片的形式存储在磁盘上。
每个数据分片都包含一个用于范围剪枝的稀疏主索引,并可能包含额外的辅助数据跳过索引,例如 minmax、set 或布隆过滤器索引。
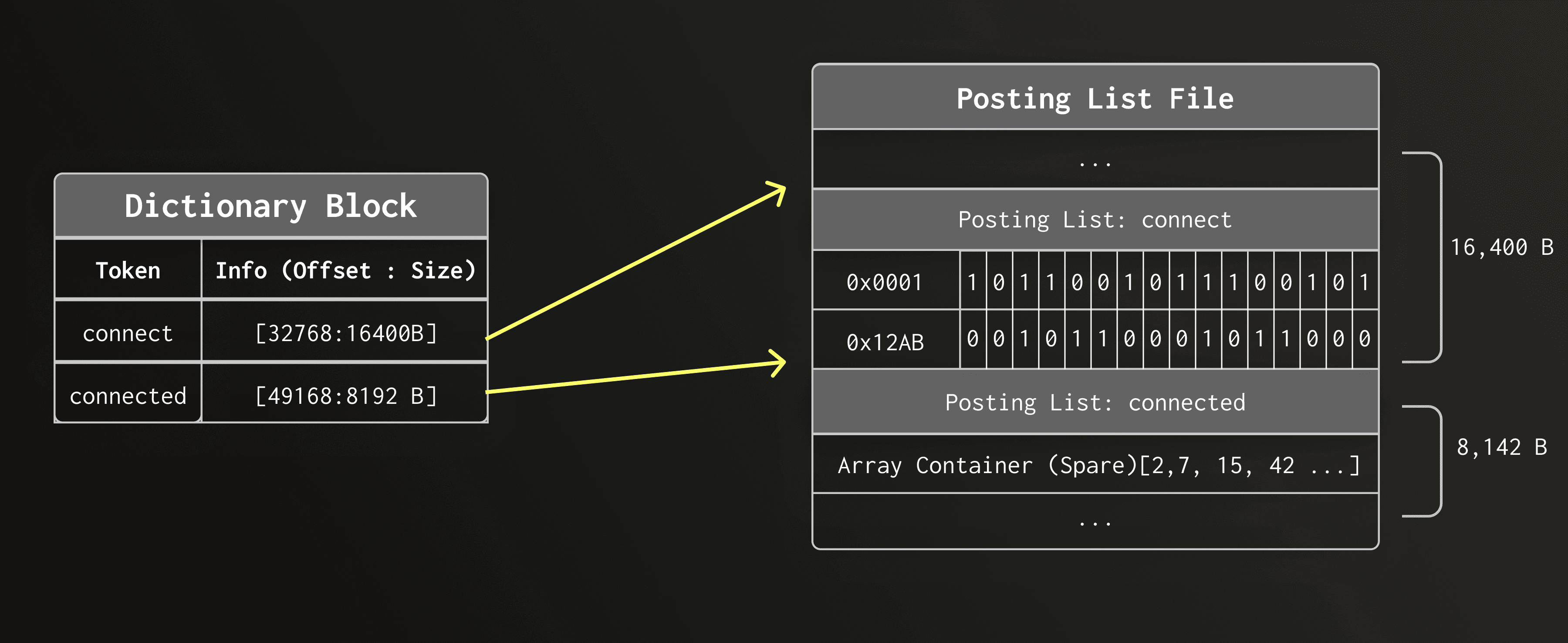
文本索引属于第二类索引。与其他数据跳过索引一样,它也是为那些需要对其文本内容进行索引以实现快速全文搜索的列定义的。它与列文件和主索引一起存储在每个数据分片中,如下图所示。
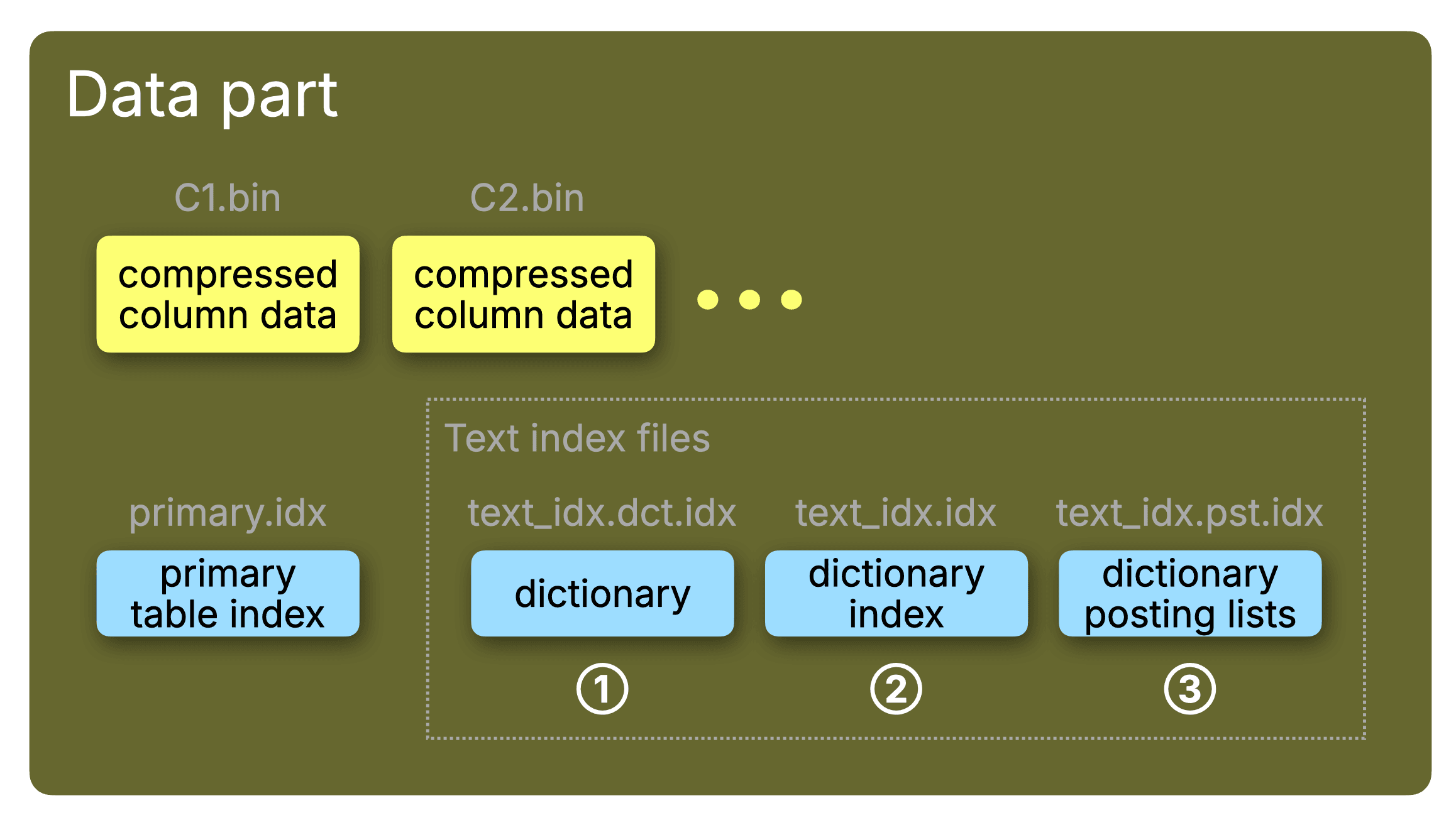
如上图所示,文本索引内部由三个主要组件构成,每个组件在每个数据分片中都以独立文件的形式存储:
① 字典 文件 (text_idx.dct.idx);
② 稀疏字典索引 文件 (text_idx.idx);
③ 倒排列表 文件 (text_idx.pst.idx)。
为清晰起见,这些文件名将在后续图中用到。
在以下章节中,我们将逐一介绍每个索引组件。
① 适用于对象存储的字典布局
字典是文本索引中负责存储所有已索引词元的部分。它为每个词元提供一个指向相应倒排列表的引用,该列表记录了所有包含该词元的行位置。
早期文本索引版本中的字典基于一种名为 有限状态传感器 (FST) 的数据结构,其本质是一个带有前缀和后缀压缩的 Trie 树。FST 在本地 SSD 上能提供紧凑的存储和快速的查找能力。然而,FST 也高度依赖大量小规模的随机读取,当索引存储在对象存储上时,这种模式会变得极其低效。
基于此,我们重新设计了字典布局,并设定了两个目标:首先,我们希望优先采用顺序访问模式,而非随机读取。其次,由于索引查找中无法完全避免随机查找,我们希望能将每个查询的随机查找次数降到最低。这样,即使索引数据集不断增长,也能确保端到端查询延迟保持在较低且可预测的水平。
为此,新的文本索引字典采用了基于块的布局:词元(tokens)按字母顺序排序,并被分组为固定大小的块,每个块包含 dictionary_block_size 个条目(默认为 512)。
这种设计实现了顺序读取、高效压缩以及快速访问倒排列表 (Posting Lists),这些优势将在后续章节中详细描述。
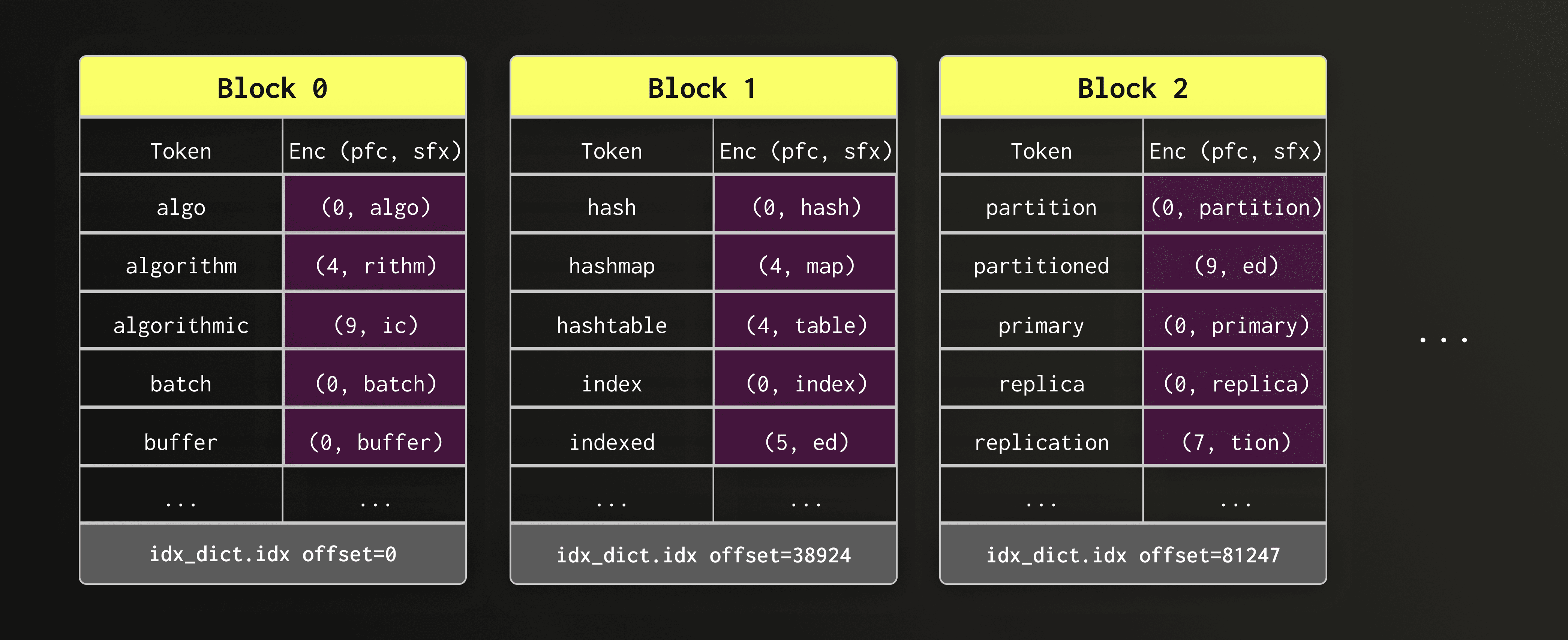
字典块的顺序读取
下图展示了同一字典文件(text_idx.dct.idx)中位于不同偏移位置的多个字典块。

每个块都是一个自包含的、经过排序的词元(token)数据块,可以进行顺序读取。
顺序读取数据块可避免分散的随机访问,即使索引文件位于对象存储上,也能保持高效的查找性能。
块内的前缀编码压缩
仔细观察这些数据块,我们可以立即发现连续的词元(token)通常共享一个共同的前缀——例如,“algo”、“algorithm”和“algorithmic”。为每个词元存储完整的字符串会造成资源浪费。
为了在不牺牲顺序布局的前提下保持字典块的紧凑性,新设计采用了前缀编码(front-coding)来压缩词元。该压缩方法将每个块的第一个词元完整存储。而后续的每个词元则被替换为与前一个词元共享的前缀长度,以及其自身的后缀。
前缀编码显著减少了数据块在磁盘上的占用空间。
在下图中,词元列仅为方便阅读而显示;在磁盘上,实际只存储编码后的 (prefix_length, suffix) 值(图中以紫色突出显示)。
字典块中的倒排列表偏移量
在文本搜索过程中,一旦在字典中找到一个词元(token),搜索引擎就必须定位该词元所出现的行。每个词元的这些行位置信息会存储在倒排列表(Posting List)中。
因此,每个字典条目都存储一个指向倒排列表文件(text_idx.pst.idx)的字节偏移量,使得 ClickHouse 能够直接跳转到特定词元的倒排列表。
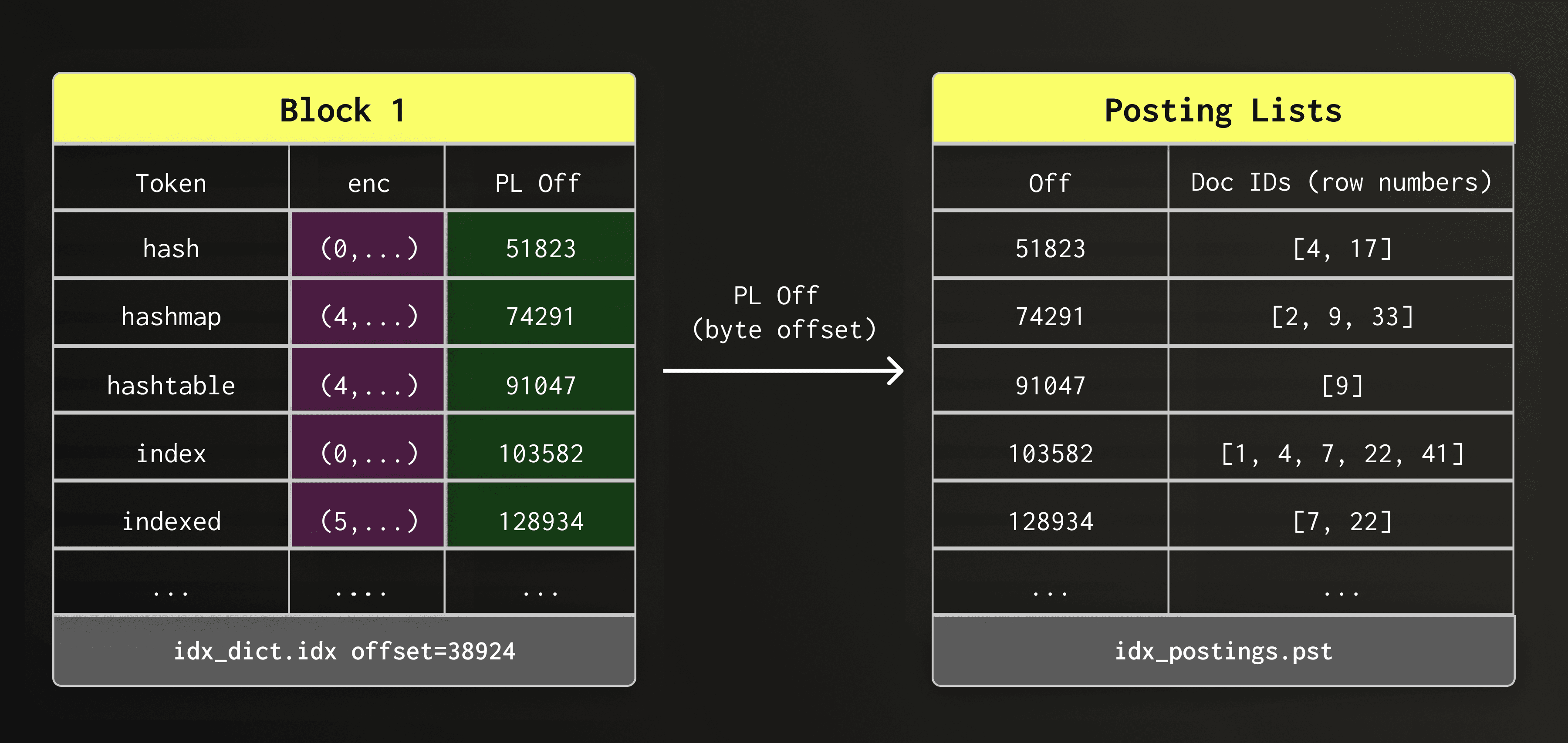
为简化起见,图中仅以概念形式呈现了数据组织;对于实际倒排列表 (posting lists) 的存储,我们采用了特殊实现方案,稍后将详细描述。
至此,我们已经探讨了字典布局,它是构成新文本索引的三个主要组件中的第一个。接下来,我们将探讨稀疏索引 (sparse index),它能让 ClickHouse 无需扫描整个字典文件,便能快速找到正确的字典块 (dictionary block)。
② 稀疏索引:实现字典的快速查找
鉴于数百万个词元 (token) 可能分散在数千个字典块 (dictionary block) 中,我们需要一种快速方法来找到包含特定词元的正确字典块。
当然,我们可以加载或遍历所有字典块(或在其中执行二分查找),但这种做法的性能将无法接受。
稀疏索引通过记录每个字典块的首个词元 (token) 及其在该字典文件 (text_idx.dct.idx) 中的字节偏移量,解决了上述问题。
稀疏索引本身存储在一个单独的文件 (text_idx.idx) 中。与字典块和倒排列表相比,稀疏索引非常小巧,因此能始终驻留在内存中。
下图展示了稀疏索引文件 (text_idx.idx) 如何指向字典文件中位于不同偏移位置的字典块。
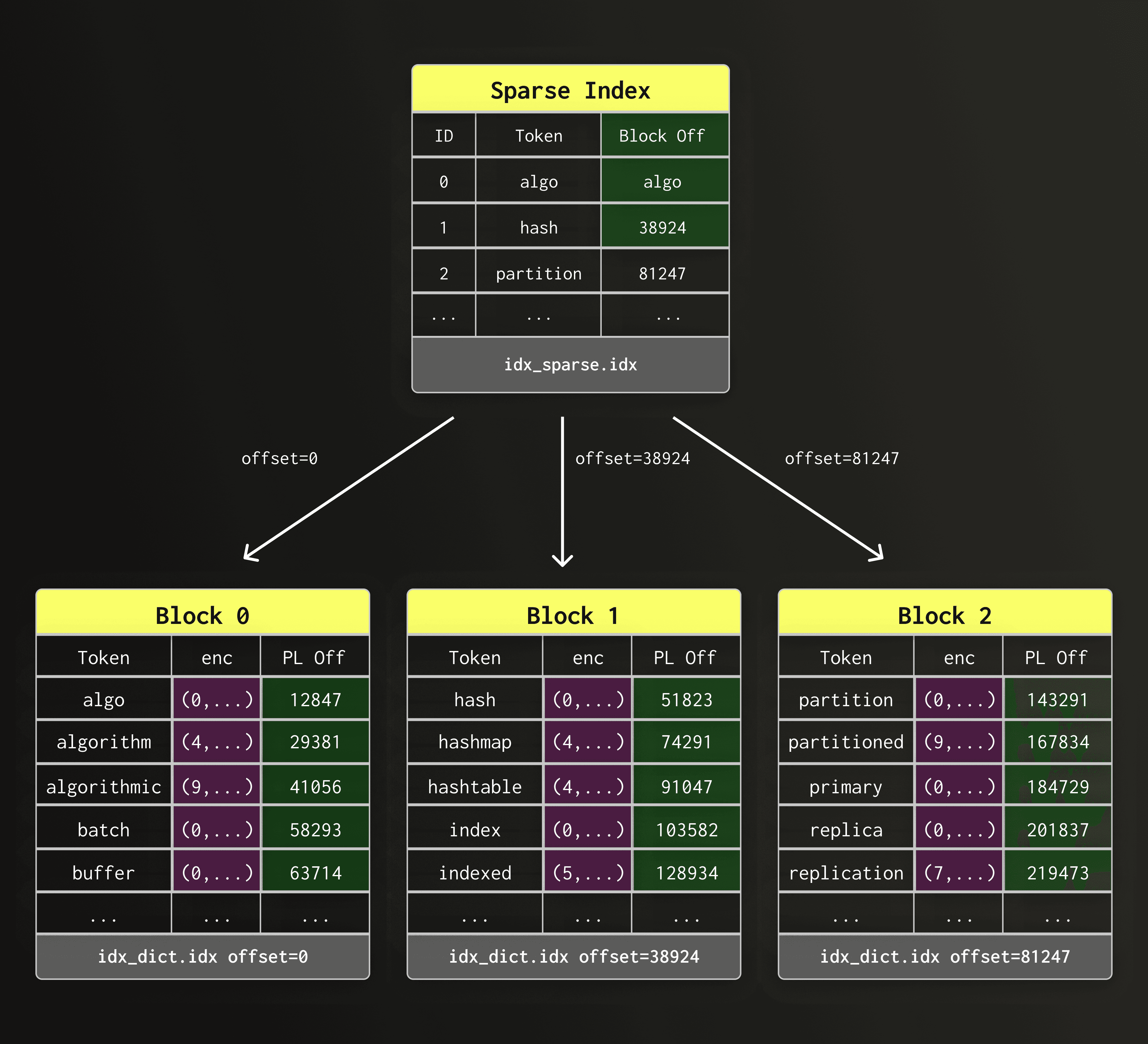
如果你熟悉 ClickHouse 的主键索引 (primary key index) 的工作原理,那么这种设计会让你感到熟悉——事实上,这两种索引都采用了类似的“稀疏索引”机制:它们为每个数据块存储一个入口点,允许系统快速跳转到数据所在的大致区域,然后从该区域开始顺序扫描。不同之处在于,这里的块包含的是字典词元,而非行值。
稀疏索引和字典块最大限度地减少了随机 I/O,并使查找过程主要以顺序方式进行,从而确保了字典访问在本地磁盘和对象存储 (object storage) 上的高效性。
有了字典块 (dictionary block) 和稀疏索引,引擎便能高效地定位词元。
下一步是读取倒排列表 (posting list),它存储了词元出现的行所在位置。
③ 倒排列表:将词元映射到行位置
在上一节中,我们采用了一种简化的布局来展示字典条目如何引用磁盘上的倒排列表。
实践中,倒排列表(Posting lists)的大小可能差异巨大。有些 token 在数据集中仅出现一两次,而另一些则可能在数百万行中出现。
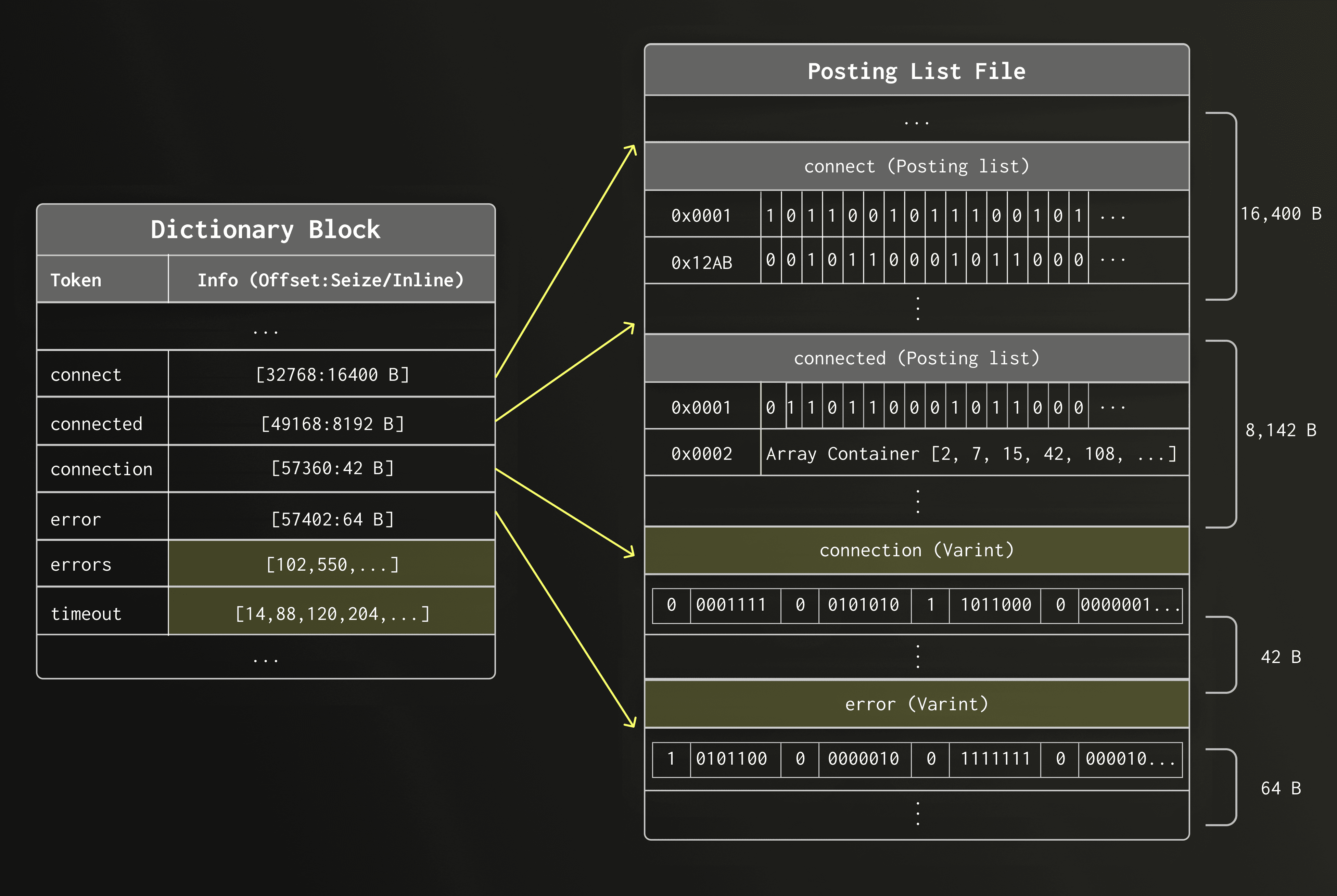
为了高效地表示各种大小的倒排列表,ClickHouse 的新文本索引会根据倒排列表的实际大小,采用不同的存储方式:
Roaring bitmap 倒排列表 — 适用于行 ID 数量超过 12 的倒排列表;
VarInt-encoded 倒排列表 — 适用于行 ID 数量在 7 到 12 之间的倒排列表;
Embedded 倒排列表 — 适用于行 ID 数量小于或等于 6 的倒排列表。
下文将详细介绍每种表示方式。
Roaring bitmap 倒排列表(行 ID 数量 > 12)
包含超过 12 个行 ID 的倒排列表,以 Roaring Bitmap (Roaring 位图) 的形式存储。
Roaring Bitmap 是一种压缩位图,能够存储大量 32 位整数,并支持快速的交集 (intersections) 和并集 (unions) 操作。这两种操作对于组合多个倒排列表的 SQL 函数(例如 hasAnyTokens() 和 hasAllTokens())至关重要。
内部结构
Roaring Bitmaps 将 32 位整数空间划分为两部分。上半部分基于行 ID 的高 16 位,代表 65,536 种不同的可能值。
下半部分则存储在三种不同的容器之一中。这些容器会根据所包含的行 ID 数量,选择最紧凑的内部表示方式:
Array container (数组容器) — 适用于稀疏块;
Bitmap container (位图容器) — 适用于密集块;
Run-length container (游程编码容器) — 适用于包含大量连续游程的块。
这种自适应的内部结构使得 Roaring Bitmaps 能够高效地压缩内部数据分布差异巨大的倒排列表,同时仍能实现快速的集合操作。
示例
为了理解其重要性,请考虑在一个大型文本数据集中出现的 token connect。假设 connect 出现在行 ID 65,536、65,538、65,539、65,542,以及表中散布的数万个其他行 ID 中。如果将这些数字存储为普通的 32 位整数排序数组,每个条目将占用 4 字节,这意味着仅存储 50,000 个匹配行就需要大约 200 KB。
使用 Roaring Bitmaps,每个值的高 16 位(0x0001)标识了容器 — 一个负责处理行 ID 范围在 65,536–131,071 之间的桶。低 16 位(0x0006)是存储在该容器内部的值。在此示例中,所有四个行 ID 都落入同一个容器。
每个容器会根据其包含的行 ID 分布独立选择其内部结构:
磁盘布局
对于大型倒排列表 (posting lists),Roaring Bitmaps 表现极为出色:它们不仅提供了良好的压缩能力,还能在搜索期间高效执行多条倒排列表的求交集等查询操作。
Roaring Bitmaps 的倒排列表在内部被进一步划分为块(由 posting_list_block_size 参数控制)。每个块记录其包含的最小和最大 row ID。这些元数据(metadata)使得查询引擎 (query engine) 能够跳过解压缩那些其 row ID 范围已被其他谓词 (predicate) 排除的块,从而减少搜索过程中的不必要工作。
局限性
然而,Roaring Bitmaps 由于其强制性元数据,存在一个不容忽视的最小存储体积。这种开销对于大型倒排列表 (posting lists) 来说微不足道,但对于较小的倒排列表则会造成浪费。因此,引入针对稀疏词元 (sparse tokens) 的专用表示方法变得至关重要,因为稀疏词元在自然语言和文本数据集 (text datasets) 中非常常见。ClickHouse 的倒排索引 (inverted index) 为此类情况采用了两种额外的表示形式。
VarInt 编码的倒排列表 (posting lists)(7–12 个 row ID)
对于包含 7 到 12 个 row ID 的小型倒排列表,文本索引将 row ID 存储为 VarInt 压缩整数的简单序列。
VarInt 将每个字节拆分为 7 位数据(即“有效载荷”位)和一个延续位。因此,小于 128 的值仅需一个字节,小于 16,384 的值需两个字节,依此类推。
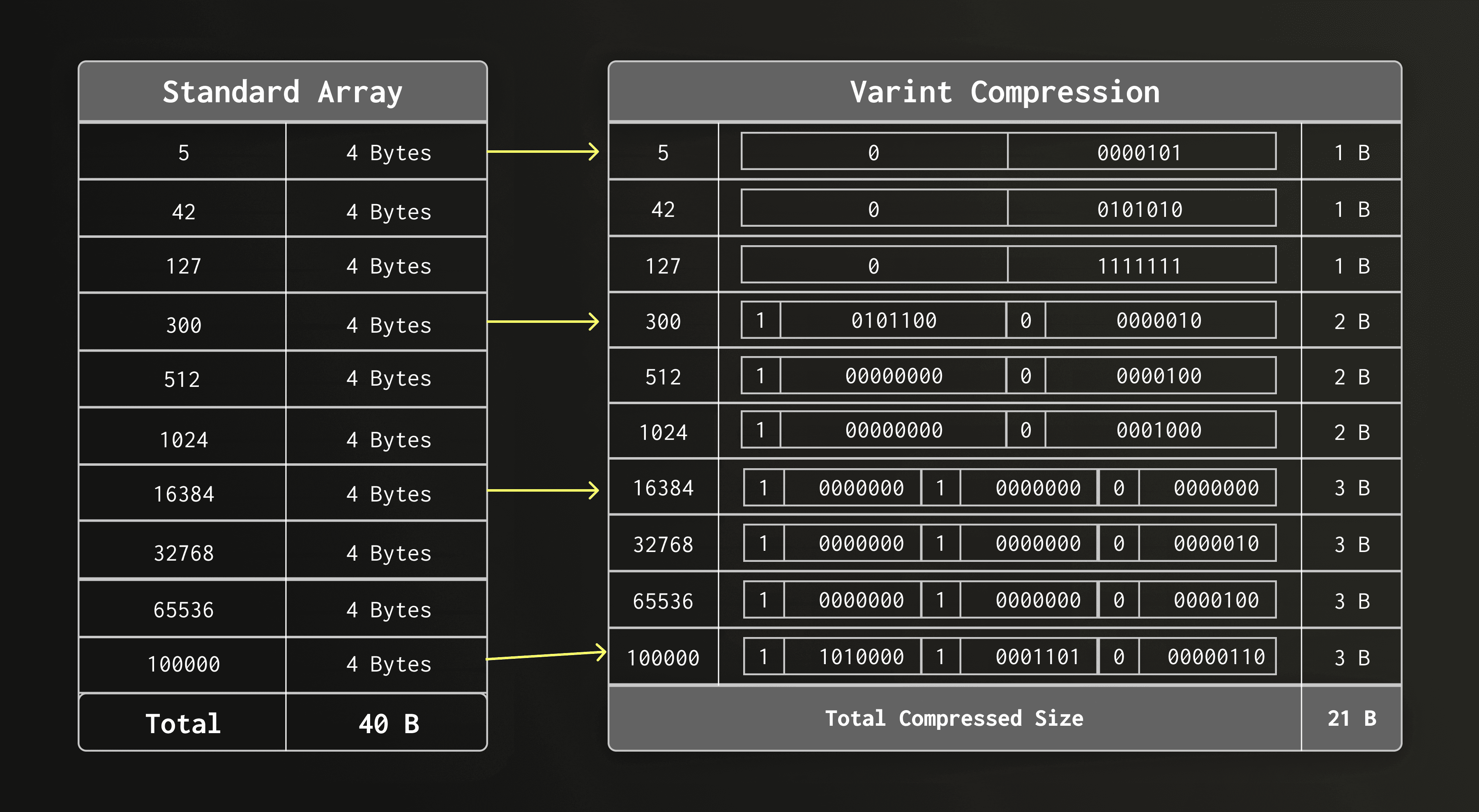
由于小型倒排列表中的 row ID 通常是相对较小的整数,这种 VarInt 编码在平均情况下能实现非常好的压缩效果。例如,一个包含 12 个 row ID 的倒排列表通常只占用几十个字节。
为何此处不采用 Roaring Bitmaps
对于此类倒排列表 (posting lists),使用 Roaring Bitmaps 会导致效率低下,因为其序列化结构由于头部和容器元数据的原因,存在大约 48 字节的最小体积。因此,一个简单的 VarInt 列表是更小、更简单的替代方案。
嵌入式倒排列表 (posting lists)(≤ 6 个 row ID)
在文本索引的开发过程中,我们发现在实际数据集 (real-world datasets) 中,绝大多数的独立词元 (distinct tokens) 都具有非常低的基数 (cardinality)。我们研究了两个庞大且差异显著的数据集:
一个包含 217.9 亿个独立词元的内部日志文件数据集;
一个包含 255.1 亿个独立词元的自然语言网络语料库 (Fineweb, https://huggingface.co/datasets/HuggingFaceFW/fineweb )。
两个数据集上的结果均保持一致:
所有词元中,分别有 94.5% 和 90.2% 出现在六行或更少行中;
词元基数的中位数分别为 2 和 1;
只有 3% 和 6.1% 的词元基数(cardinality)大于 12,而低于这个阈值时,Roaring Bitmaps 会产生静态开销(static overhead);
为嵌入式倒排列表 (embedded posting lists) 设定的六行阈值,是出于内存布局考量而选定,结果在两个数据集中均能在 P90 级别涵盖 90% 的词元(这虽是巧合,但却是一个近乎完美的经验性拟合)。
为何独立存储小规模倒排列表 (posting lists) 会造成资源浪费
对于大多数词元,使用 Roaring Bitmap 的完整机制——包括其容器元数据(container metadata)和独立的索引文件条目(file entry)——将带来显著的开销(overhead)。如果倒排列表包含六个或更少元素,索引就可以完全避免写入倒排列表文件。
嵌入式布局 (Embedded layout)
相反,如果一个词元出现在六行或更少行中,行 ID (row ID) 将直接嵌入到字典条目(dictionary entry)中,取代了指向倒排列表文件的字节偏移量(byte offset)。因此,可以无需额外的间接寻址(indirection)和磁盘访问(disk access)即可读取整个倒排列表。
与小对象优化(small-object optimizations)的关系
这一思路受到了系统编程中所谓的小对象优化(small-object optimization,例如 SSO、Short String Optimization)的启发,即极小的值以内联方式(inline)存储,而非存储在单独的位置。对于稀有词元(在自然语言数据集中极为普遍),这种方法既消除了存储开销(storage overhead),也避免了额外的 I/O。
至此,我们已经介绍了新文本索引的三种主要数据结构:字典块(dictionary blocks)、稀疏索引(sparse index)和倒排列表(posting lists)。
在深入探讨这些组件在查询执行(query execution)期间如何协同工作之前,我们先简要探讨一下分片合并(part merges),文本索引的布局在此过程中同样扮演着重要角色。
文本索引的高效合并
如前所述,文本索引以三个独立文件的形式存储在每个数据分片(data part)中:字典(dictionary)、稀疏索引(sparse index)和倒排列表(posting lists)。
ClickHouse 在后台持续将较小的数据部分合并为较大的数据部分,并重写合并后的所有文件。当这些文件位于对象存储(object storage)上时,合并性能很大程度上取决于访问模式。
新的文本索引布局旨在支持合并期间高效的顺序访问。由于字典块(dictionary blocks)已按排序顺序存储,文本索引无需从头开始重建。相反,ClickHouse 可以沿用其处理表行数据时所使用的同一种单次合并处理(single merge pass)方式,对它们进行合并。
在合并过程中,两个数据部分的字典会被顺序读取,并交错(interleaved)到一个新的已排序字典中,从而避免随机 I/O,并使索引合并即使在索引文件位于对象存储上时也能保持高效。
下方的动画展示了两个数据部分的合并过程。为突出重点,我们仅展示了字典文件的合并,而数据部分的其他文件也在同一次处理中完成合并,但未在动画中展示。
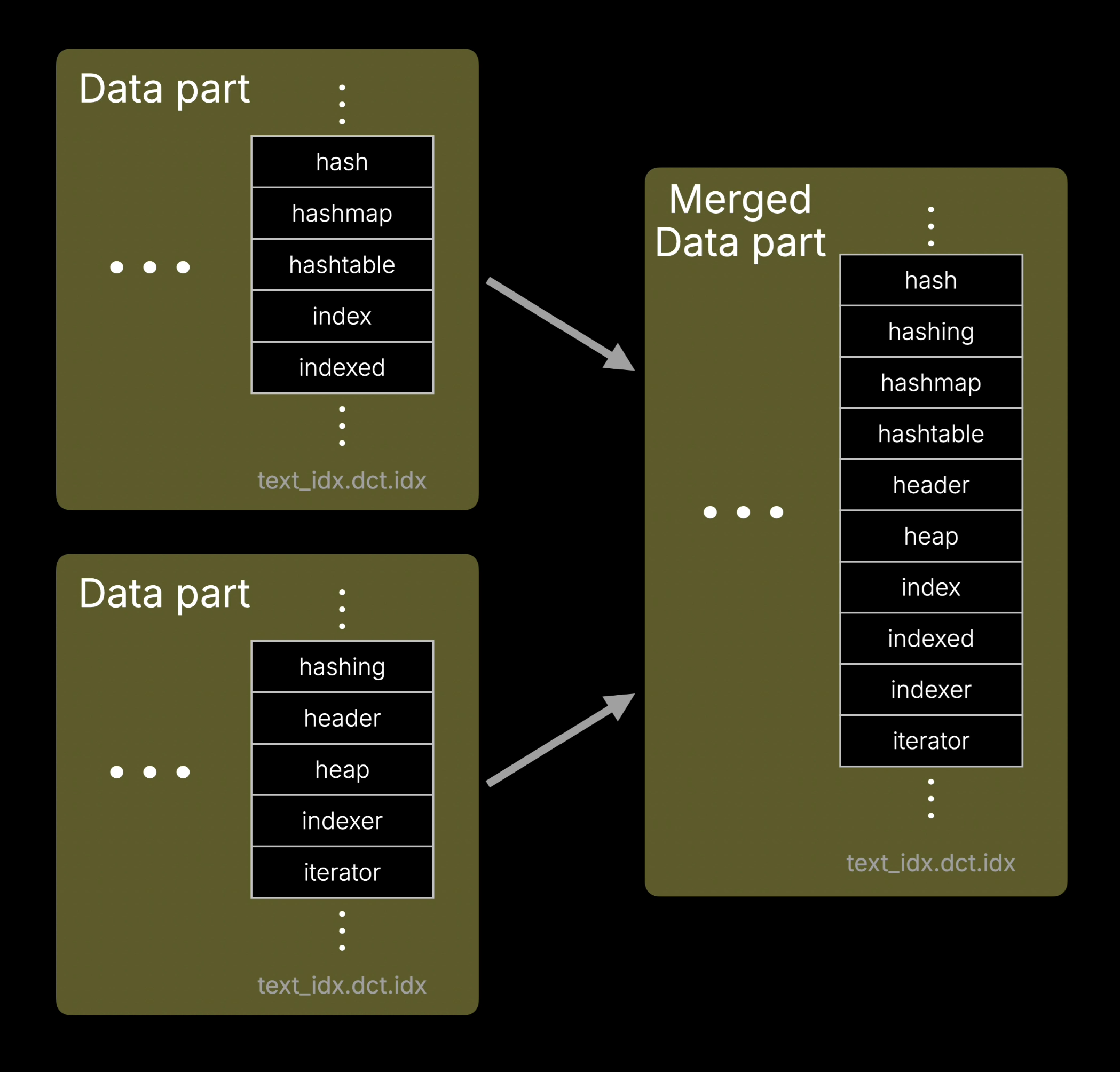
上述动画中未展示的是,倒排列表文件 (text_idx.pst.idx) 中的倒排列表(posting lists)会在同一次处理中,通过使用主数据部分合并时生成的行 ID 映射来重新映射行号,从而进行更新。这样一来,就无需再次读取原始文本列。
因此,合并文本索引的操作十分轻量化,其扩展性取决于索引本身的大小,而非取决于原始文本数据的大小。
上述动画中同样未展示的是,稀疏索引文件 (text_idx.idx) 会根据合并后的字典块,为合并后的数据部分进行重建。
在介绍完数据部分合并后,我们现在将回到查询执行环节,探讨字典块、稀疏索引和倒排列表在搜索过程中如何协同工作。
查询引擎如何使用文本索引
考虑以下带文本索引的表
复制代码CREATE TABLE docs(\`key\` UInt64,\`doc\` String,INDEX idx(doc) TYPE text(tokenizer = splitByNonAlpha))ENGINE = MergeTree()ORDER BY key;
以及以下查询
SELECT count() FROM docs WHERE hasToken(doc, 'clickhouse');在这里,我们正在搜索令牌(token)clickhouse。
接下来,我们深入了解当此查询运行时内部发生的情况。
步骤 1 — 查找匹配的行号
我们首先需要确定哪个字典块(dictionary block)包含令牌 clickhouse。
顺序扫描所有块的成本会过高。因此,我们利用稀疏索引(sparse index)来定位到正确的块。
由于稀疏索引 (sparse index) 仅包含每个数据块的第一个词元 (token),我们使用上界 (upper bound) 进行二分查找 (binary search) 以定位候选数据块。搜索词元通常不出现在稀疏索引本身中,但上界会指示如果该词元存在于索引中,它应该位于哪个数据块。
值得注意的是,稀疏索引相对较小,并始终保存在主内存中。因此,二分查找本身仅需几微秒即可完成。
在下图中,稀ᅳ疏索引查询会返回一个条目,该条目对应的字典块 (dictionary block) 可能包含 clickhouse。该条目的偏移量 (offset) 会指明应从字典文件 (dictionary file) 中读取哪个数据块。

接下来,我们顺序读取找到的字典块,并扫描其中的词元。
由于字典存储在对象存储 (object storage) 上,块扫描 (block scan) 的速度与块内进行点查找 (point lookup) 的速度大致相当——其运行时长主要受限于发送请求和获取结果的延迟。
在下图中,稀疏索引为我们提供了字典文件中候选字典块的偏移量。我们顺序读取此数据块并进行扫描,直到找到 clickhouse。
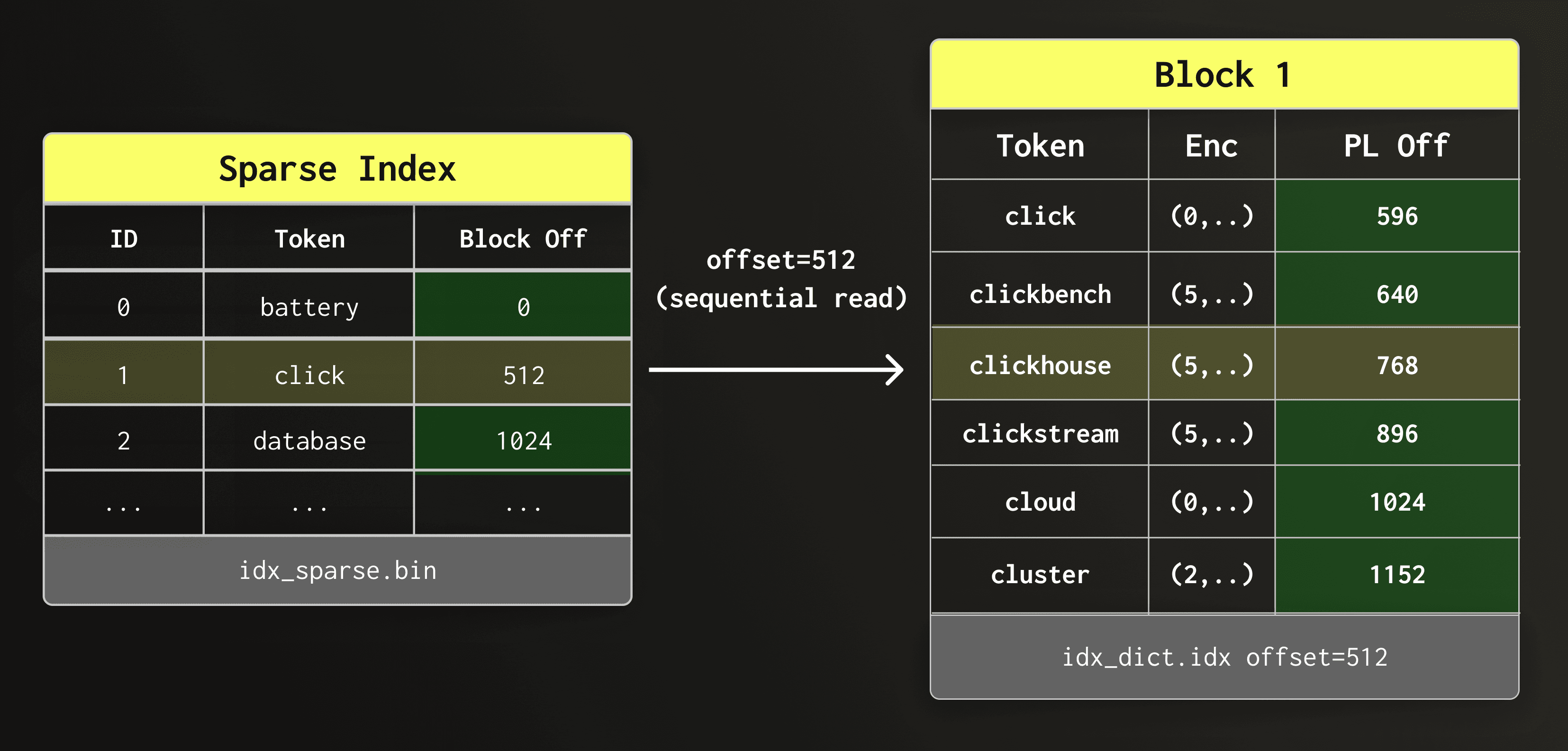
一旦在字典块中找到 clickhouse,我们便会从倒排列表 (posting list) 文件中读取关联的倒排列表。
在下图中,候选字典块会提供倒排列表文件中倒排列表的偏移量。随后我们便可检索该倒排列表。
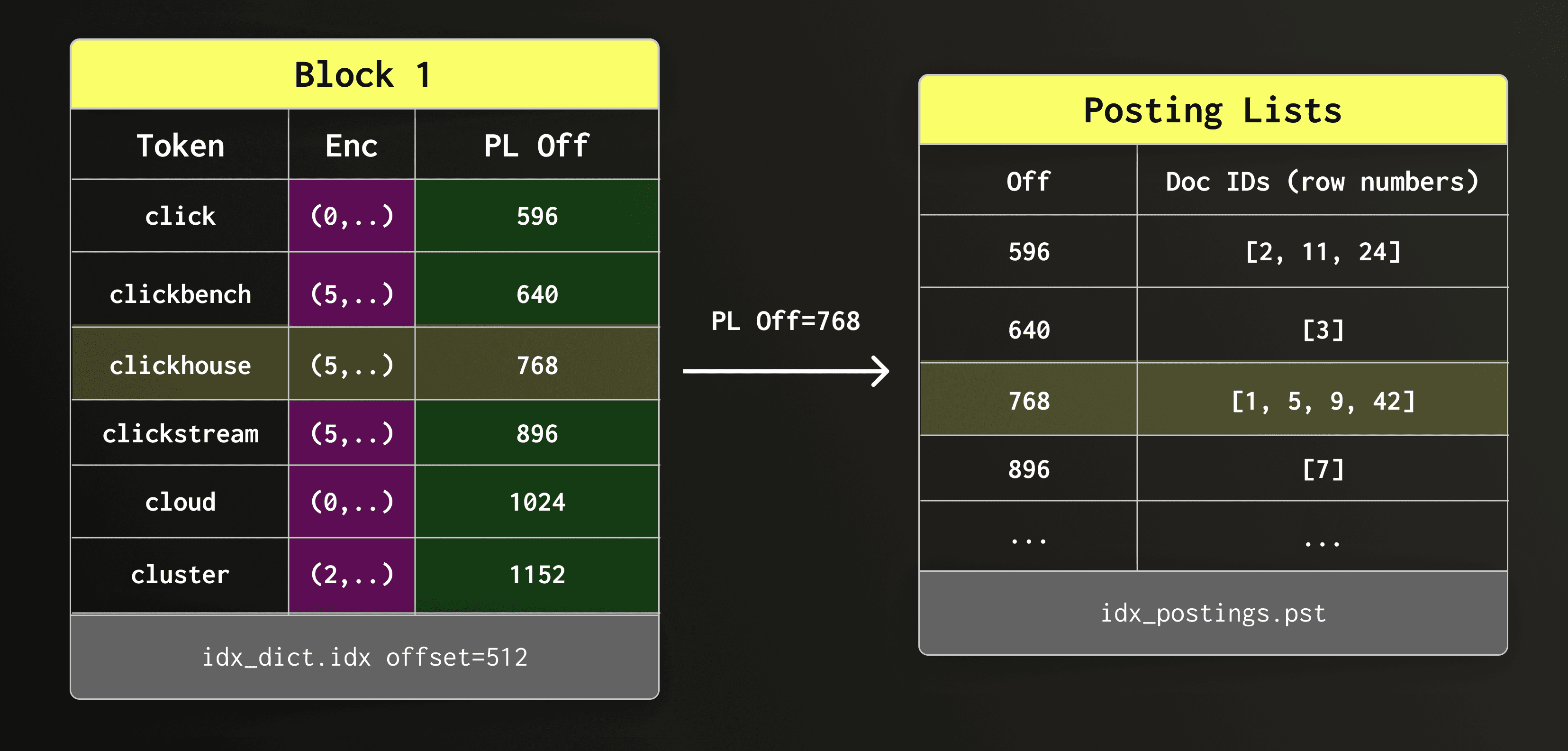
检索到的倒排列表包含了所有匹配的行号。
引擎现在需要决定在执行过程中如何对其进行应用。
步骤 2 — 选择执行模式
索引查询会将匹配行的行号 (row numbers) 作为数据部分列 (data part columns) 中的偏移量 (offsets) 返回。
根据查询的结构和所使用的文本搜索功能,ClickHouse 可以通过三种不同的方式应用这些偏移量,其效率从高到低排列。
引擎可以根据偏移量构建一个虚拟列,并据此实现以下任一目的:
完全避免读取已索引的文本列;
在检查剩余行之前,利用该虚拟列缩小候选集。
对于更复杂的搜索模式,引擎将回退到经典的跳跃索引评估模式。在此模式下,索引仅用于跳过那些确定不包含匹配项的数据颗粒。
在接下来的三个部分中,我们将详细描述这三种方法。
步骤 2A — 直接读取模式
文本索引在 ClickHouse 的跳跃索引中具有特殊性:其倒排列表(posting list)包含与查询匹配的精确行号——这意味着不会出现误报,也无需进行任何额外的过滤。
鉴于我们已经精确知晓匹配行,可以直接跳过常规的过滤步骤,转而进行行级掩码操作。
通过虚拟列实现行级掩码
我们利用倒排列表中的行 ID 来构建一个虚拟布尔列。该列是一个内部列,仅在查询执行期间存在。我们将所有匹配的行设置为 1,其余行设置为 0。
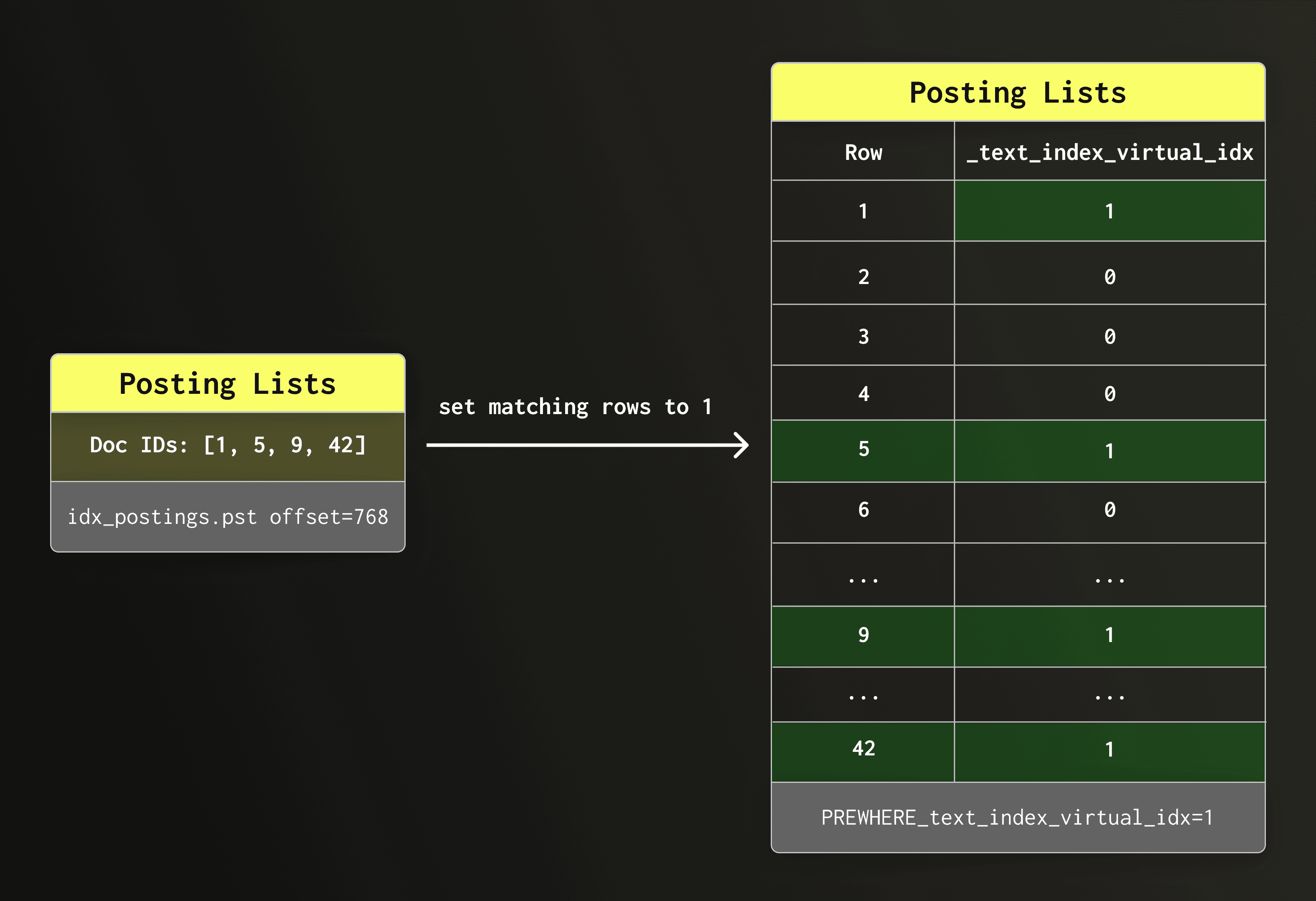
PREWHERE 查询重写
ClickHouse 会自动重写查询,以便根据该虚拟列进行过滤。例如,以下查询:
SELECT count() FROM docs WHERE hasToken(doc, 'clickhouse');将被重写为:
SELECT count() FROM docs PREWHERE _text_index_virtual_idx = 1;PREWHERE 执行
PREWHERE 子句会在其他 WHERE 条件执行之前评估其自身条件。这意味着只有匹配的行才会被传递到下一个处理步骤(即 WHERE 阶段)。未匹配的行将尽可能早地被排除,从而有效减少 I/O 开销以及后续操作符需要处理的行数。
多词元处理
当查询涉及多个词元时——例如,包含多个 hasToken 条件,或调用 hasAnyTokens/hasAllTokens 函数处理多个词元——每个词元都会独立地执行相同的查找过程,并生成各自的倒排列表。随后,系统会利用这些倒排列表之间的位运算来填充虚拟列:对于连接条件(所有词元都必须匹配),使用 AND 操作;对于析取条件(任意词元匹配即可),使用 OR 操作。这种方式不仅能确保行过滤的高速执行,还能有效避免逐行进行字符串评估。
为何称之为直接读取模式
我们刚刚描述的这种模式,在 ClickHouse 内部被称为“直接读取(direct read)”模式。它是利用文本索引最自然、最有效的方式。
索引文本列根本无需读取,因为查询仅利用文本索引中存储的行级信息就能得到解答。
限制与支持的函数
直接读取仅在索引令牌与搜索值完全对应且不存在误报风险时才安全。SQL 函数 hasToken、hasAnyTokens 和 hasAllTokens 均属于此种情况。
步骤 2B — 提示式直接读取
对于某些特定的谓词,常规的直接读取无法实现。例如,考虑以下查询:
SELECT col1, col2 FROM table WHERE col3 LIKE '%clickhouse performance%'将索引用作提示
为了在此处利用文本索引,ClickHouse 会对搜索模式进行标记化 (tokenize),并在索引中查找 clickhouse 和 performance 这两个令牌。然而,即使某行包含这两个令牌,也无法保证它能完全匹配整个模式。这些词可能相距甚远(例如 clickhouse has great performance),或者顺序不同(例如 the performance of clickhouse)。换言之,仅依赖索引自身可能会产生误报。不过,我们可以将索引用作“提示”,以排除那些不包含 clickhouse 和 performance 这两个令牌的行。
如果分区中的大多数行不包含这两个令牌,那么索引可以在对列执行耗时的 LIKE 评估之前,剔除大部分候选行。
提示式直接读取模式
我们将此称为“提示式直接读取”模式——虚拟列会缩小候选行集,随后,原始的 LIKE 谓词将在这些筛选后的行上进行评估。
读取倒排列表的开销
这种技巧带来的一个挑战是:读取倒排列表并非没有开销,它需要进行寻道 (seeks) 和解压缩 (decompression)。举例来说,如果令牌 “clickhouse” 出现在 80% 的行中,索引只能消除相对较少的行,但仍需为所有行承担 I/O 开销。在这种情况下,最好完全避免索引读取,直接在列上评估 LIKE 谓词。
基于选择性的决策
为此,ClickHouse 无需读取倒排列表(posting list)的实际内容,即可利用字典中已有的每个 token 的基数,来估算匹配集合的基数。如果估算结果低于或等于 text_index_hint_max_selectivity × N(默认为分区中总行数的 20%),则采用该提示:系统会读取倒排列表,填充虚拟列,并在 LIKE 检查运行前过滤掉不匹配的行。反之,如果估算结果超出此阈值,则放弃该提示:虚拟列将被设置为全 1,不进行索引 I/O 操作,所有过滤负载将由原始谓词承担。
可观测性
这两种结果以 TextIndexUseHint 和 TextIndexDiscardHint 两种 profile 事件的形式体现,通过查询日志可以观察到它们,从而了解索引是否对特定查询有所贡献。
支持的函数
支持的 SQL 函数包括:like, startsWith, endsWith, mapContainsKeyLike / ValueLike
步骤 2C — 跳过索引模式 (Skipping index mode)
当一个谓词无法利用直接读取 (direct read) 优化或提示模式 (hint mode) 的优势时,优化器会将其指定为使用 ClickHouse 的跳过索引 (skipping index) 基础设施在回退读取模式 (fallback read mode) 下执行,此时谓词会针对该列进行常规评估。
这种技术适用于更复杂的模式,例如:match, multiSearchAll, multiSearchAny。
例如,请看以下查询:
SELECT col1, col2 FROM table WHERE match(col3, 'connect.*timeout')像这样的正则表达式谓词无法分解成一组可靠的 token,因为该模式表达了索引无法验证的序列和邻近性约束。因此,优化器会以经典读取模式 (classical read mode) 对其进行评估:
文本索引在数据粒度 (granule) 级别上发挥作用,它会检查每个数据粒度是否包含可能满足该模式的 token,并跳过那些不满足的粒度。
为什么这种方式比直接读取慢
对于每个通过此粗粒度过滤的数据粒度 (granule),引擎必须完全解压 col3 列,并逐行扫描以对实际的字符串数据评估正则表达式。文本列通常存储宽度较大且解压成本高昂,而且匹配常用词的模式可能导致大部分数据粒度都被保留为候选。虽然索引在数据粒度边界减少了 I/O 操作,但主要成本(解压和扫描列)依然存在。
这正是直接读取 (direct read) 模式为支持其的谓词所弥补的差距:它无需解压列来确认索引已知的信息,而是直接利用倒排列表 (posting list) 的结果。
至此,我们已经介绍了文本索引的内部设计以及查询是如何在其上执行的。
在下一节中,我们将从实现细节转向配置和使用。
定义文本索引
如果您希望在深入了解以下细节之前,先快速实践一下,可以观看下方短视频,了解如何在 ClickHouse 中创建和使用文本索引。
https://www.youtube.com/watch?v=9zPmf1a_heU
在了解如何创建文本索引之前,我们先看看哪些列类型可以建立索引。
文本索引可以定义在 String 和 FixedString 类型的列上,以及包含字符串的 Array 和 Map 列上。
Nullable 和 LowCardinality 字符串也受支持,并且所有这些数据类型都可以混合搭配,例如 Array(Nullable(FixedString))。
接下来,我们看看如何创建文本索引。
创建文本索引
为表添加索引有两种方式:一是在表创建时,作为 CREATE TABLE 查询的一部分;二是对现有表运行 ALTER QUERY。两种方法的索引参数相同。更多详情请参阅文档。
语法:
复制代码CREATE/ALTER TABLE...INDEX text_idx(str) TYPE text(-- Mandatory parameters:tokenizer = splitByNonAlpha| splitByString[(S)]| ngrams[(N)]| sparseGrams[(min_length[, max_length[, min_cutoff_length]])]| array-- Optional parameters:[, preprocessor = expression(str)]-- See documentation for optional advanced parameters...)...
例如:
复制代码CREATE TABLE my_table(key UInt64,str String,INDEX text_idx(str) TYPE text(tokenizer = ‘splitByNonAlpha’,preprocessor = lower(str)))ENGINE = MergeTreeORDER BY key
这将创建一个文本索引,它会首先将插入到“str”列中的任何字符串转换为小写,然后根据非字母数字字符进行拆分,并将其存储在上述经过搜索优化的文本索引结构中。例如,“HeLlo my1!!!NAME&is,234234”将被拆分为 [‘hello’, ‘my1’, ‘name’, ‘is’, ‘234234’],从而可以对这些词元进行快速搜索。
在执行任何搜索操作之前,我们先来了解一下索引参数,特别是分词器 (tokenizer) 和预处理器 (preprocessor)。
索引参数和分词
分词 (Tokenization) 和预处理 (Preprocessing) 是文本索引的两个关键组成部分,它们使文本索引区别于其他索引,并能对包含噪声的文本数据进行轻松、快速的搜索。这两个组件协同工作,可在数据插入 (INSERT) 时实现强大、自动化的数据转换,并提供直观的搜索结果,例如搜索 cafe 时能够匹配 'cafe'、'café'、'Café'、'CAFÉ' 等。
接下来,我们来详细了解一下。
预处理
预处理器会在分词 (Tokenization) 之前对输入列执行。与在创建索引时直接应用于输入列的函数(例如 INDEX idx(lower(col)))不同,ClickHouse 会自动将预处理器表达式应用于在相同索引列上运行的专用文本搜索函数,例如:hasToken、hasAllTokens 和 hasAnyTokens。结合 ClickHouse 广泛的字符串函数列表,我们可以构建一个强大的预处理管道,实现文本小写转换、去除重音符、处理 HTML、应用 UTF8 规范化等功能!
预处理器的语法如下:
preprocessor = expression(<column-name>)注意事项:
expression() 可根据需求任意简化或复杂化,可以包含任意数量的嵌套函数(但请注意,这些函数将在每行插入的数据上运行);
表达式函数必须是确定性的;
必须与索引定义匹配,即如果您的索引定义为 INDEX (lower(col1)) ,那么预处理器表达式也必须在 lower(col1) 上调用。此规则是强制执行的。
示例
场景 1:输入数据是人工生成的文本,包含大小写混合的字符和标点符号。索引会将文本转换为小写,从而在搜索时实现大小写不敏感的匹配。
复制代码preprocessor = lower(col)Input: 'Hello World! My_Name IS John123'Preprocessed: 'hello world! my_name is john123'
场景 2:输入数据包含多行字符串,但只有第一行字符串与搜索相关。
复制代码preprocessor = substringIndex(col, '\n', 1)Input: 'Hello World\nSecond Line\nThird Line'Preprocessed: 'Hello World'
场景 3:输入数据由 HTML 字符串组成,预处理器首先移除 HTML 元素(并将其替换为空格),然后将结果转为小写。
复制代码preprocessor = lower(extractTextFromHTML(col))Input: 'Hello WorldMy Name IS Sarah456'Preprocessed: 'hello world my name is sarah456'
场景 4:输入数据包含大小写混合、带变音符号的文本(例如法语、德语等)。首先对文本应用 大小写折叠,然后去除结果文本中的变音符号(重音符号)。
复制代码preprocessor = removeDiacriticsUTF8(caseFoldUTF8(col))Input: 'Héllo Wörld ÑOÑO Ångström'Preprocessed: 'hello world nono angstrom'
完成预处理后,我们现在将探讨分词 (tokenization),它定义了如何将输入文本分割成词元 (token) 以进行索引。
分词 (Tokenization)
这是实现目标的关键一步,分词器 (tokenizer) 规定了列中的数据行应如何被分割成词元。这是一个关键性决策,因为它将影响哪些查询能够匹配索引,哪些不能。例如,一个按空格分割数据的索引将无法匹配单词的一部分(例如 'caf' 无法匹配 'cafe'),但一个使用 ngram 分词器且 ngram 长度为 3 的索引将使 'caf' 与 'cafe' 匹配。
分词器主要分为以下几种类型:
splitBy 分词器
splitByNonAlpha 和 splitByString 分词器,顾名思义,根据非字母数字字符或自定义分隔符来分割输入文本。这对于大多数自然语言文本(如产品评论),或者分割带有固定分隔符的特定领域字符串非常有用。
示例:
复制代码-- splitByNonAlpha‘hello my1!!!name&is,234234’ -> [‘hello’, ‘my1’, ‘name’, ‘is’, ‘234234’]-- splitByString with default ' ' separator'hello my name is John' -> ['hello', 'my', 'name', 'is', 'John']-- splitByString with custom separators [', ', '; ', '\n']'apples, oranges; bananas\npears' -> ['apples', 'oranges', 'bananas', 'pears']-- splitting csv data (custom separator ',')'hello,world,foo,bar' -> ['hello', 'world', 'foo', 'bar']
N-gram 分词器
ngrams 和 sparseGrams 分词器分别将字符串分割成固定长度和可变长度的词元。ngrams 分词器的 ngram 长度可以通过一个可选的整数参数(介于 1 到 8 之间)来指定,例如 tokenizer = ngrams(3)。如果未明确指定,默认的 ngram 大小为 3。sparseGrams 函数采用一种特殊算法,输出由 min_ngram_length 和 max_ngram_length 参数控制的可变长度 ngrams。欲了解更多信息,请查阅 sparseGrams 函数文档。
示例:
复制代码-- ngrams (default size 3)'hello' -> ['hel', 'ell', 'llo']-- ngrams (size 4)'hello' -> ['hell', 'ello']-- sparseGrams (default min_length=3, max_length=100)'hello' -> ['hel', 'hell', 'hello', 'ell', 'ello', 'llo']
其他分词器
array 分词器不执行任何分词操作,即每个行值都被视为一个词元(详见函数 array)。
'hello my name is John' -> ['hello my name is John']即将推出,unicodeWordtokenizer(分词器)将以统一的默认方式分割 ASCII 字符,并把每个非 ASCII 的 Unicode 字符单独分词,生成一个 token(词元)。这为中文、日文、韩文等非空格分隔的语言提供了基础的 tokenization(分词)支持。
'Hello世界' -> ['Hello', '世', '界']所有可用的 tokenizer(分词器)都列在 system.tokenizers 中。不过,该列表也包含了已弃用的 bloom filter indexes(布隆过滤器索引)tokenbf_v1 和 ngrambf_v1。由于它们相比 text index(文本索引)通用性更差、性能更低且使用更复杂,因此不再推荐使用。
文本索引创建完成后,我们现在可以了解如何在搜索查询中使用它了。
在查询中使用文本索引
期待已久的部分 =, IN 和 LIKE 等常见字符串搜索函数(完整列表将在后文提供)默认会利用文本索引,但我们仍推荐使用新的文本搜索函数 hasAnyTokens 和 hasAllTokens,以达到最佳效果。
使用建议的搜索功能
函数 hasAnyTokens 和 hasAllTokens 分别匹配给定 token(词元)中的任意一个或所有词元。这些函数是专门为与文本索引配合使用而设计的。由于它们没有需要维护的遗留行为,因此默认情况下能够完全利用文本索引的所有新功能,例如 preprocessor(预处理器)。
这两个函数接受两种形式的搜索词元:一种是字符串,它将使用与索引列相同的预处理器和分词器进行预处理和分词;另一种是已处理词元的数组,在这种情况下,搜索前将不再应用任何预处理或分词操作。
例子 - token 搜索
建并填充表和索引。
复制代码CREATE TABLE articles(key UInt64,str String,INDEX text_idx(str) TYPE text(tokenizer = 'splitByNonAlpha', preprocessor = lower(str)))ENGINE = MergeTreeORDER BY key;INSERT INTO articles VALUES(1, 'ClickHouse is FAST'),(2, 'fast cars and SLOW trains'),(3, 'The Quick Brown Fox'),(4, 'CLICKHOUSE is Scalable');当 hasAny/AllTokens 的输入是字符串时,预处理和分词将在搜索前执行。SELECT key, strFROM articlesWHERE hasAnyTokens(str, 'ClickHouse');-- Result:-- ┌─key─┬─str───────────────────┐-- │ 1 │ ClickHouse is FAST │-- │ 4 │ CLICKHOUSE is Scalable│-- └─────┴───────────────────────┘SELECT key, strFROM articlesWHERE hasAllTokens(str, 'clickhouse FaSt');-- Result:-- ┌─key─┬─str────────────────┐-- │ 1 │ ClickHouse is FAST │-- └─────┴────────────────────┘
当使用数组重载时,词元不会被预处理和分词,搜索将直接使用数组中的字符串进行原样匹配。
复制代码-- Notice that while 'slow' matches (since 'SLOW' was stored as 'slow' in the index), 'FAST' in row 1 does not match, despite matching the un-pre-processed text in the column, since it was stored in the index as 'fast' and 'FAST' != 'fast'.SELECT key, strFROM articlesWHERE hasAnyTokens(str, ['FAST', 'slow']);-- Result:-- ┌─key─┬─str───────────────────────┐-- │ 2 │ fast cars and SLOW trains │-- └─────┴───────────────────────────┘-- The below example only matches because the format of the input tokens is the same as that of the preprocessed and tokenized index rows.SELECT key, strFROM articlesWHERE hasAllTokens(str, ['quick', 'fox']);-- Result:-- ┌─key─┬─str─────────────────┐-- │ 3 │ The Quick Brown Fox │-- └─────┴─────────────────────┘
以下是包含上述示例的 fiddle 链接:https://fiddle.clickhouse.com/6bde1e09-4ef7-41f6-844f-7c2386e09
值得注意的是,当搜索令牌以字符串形式提供时,其格式不一定需要与原始列中的文本格式完全一致。这使得搜索可以不区分大小写和重音,能够在 HTML 内容中进行搜索而无需处理标签,并支持许多其他灵活的搜索方式。最重要的是,所有这些操作都不会修改原始数据,并且原始数据将以其原始形式返回!
示例 — 部分匹配
ngrams 分词器(tokenizer)在索引阶段将文本分解为重叠的字符序列,从而实现部分词和子字符串匹配。这对于搜索技术术语、产品名称或用户可能只知道部分单词的标识符特别有用。
创建并填充表和索引。
复制代码CREATE TABLE packages(key UInt64,str String,INDEX text_idx(str) TYPE text(tokenizer = 'ngrams', preprocessor = lower(str)))ENGINE = MergeTreeORDER BY key;INSERT INTO packages VALUES(1, 'ClickHouse - fast OLAP database'),(2, 'PostgreSQL - advanced relational database'),(3, 'Elasticsearch - distributed search engine'),(4, 'ClickHouse Cloud - serverless ClickHouse');
搜索包含部分单词的行 —— 例如,'elastic' 将匹配 'Elasticsearch',而 'house' 将匹配两个 'ClickHouse' 行。
复制代码SELECT key, strFROM packagesWHERE hasAnyTokens(str, 'elastic house');-- Result:-- ┌─key─┬─str───────────────────────────────────────┐-- │ 1 │ ClickHouse - fast OLAP database │-- │ 3 │ Elasticsearch - distributed search engine │-- │ 4 │ ClickHouse Cloud - serverless ClickHouse │-- └─────┴───────────────────────────────────────────┘
使用 hasAllTokens 要求所有多个部分令牌都必须存在。
复制代码SELECT key, strFROM packagesWHERE hasAllTokens(str, 'postgres sql');-- Result:-- ┌─key─┬─str─────────────────────────────────────────┐-- │ 2 │ PostgreSQL - advanced relational database │-- └─────┴─────────────────────────────────────────────┘
值得注意的是,ngrams 索引比 splitByNonAlpha 等基于单词的索引更大,并且在索引扫描阶段可能会产生更多的假阳性结果(尽管最终查询结果始终是精确的)。因此,它们最适合在确实需要部分词匹配的场景下使用,而不应作为默认选择。
示例 — 数组数据
array 分词器(tokenizer)非常适合本身就是 Array(String) 类型的列——其中每个数组元素都会被视为一个独立的令牌,无需任何预处理器。这是用于存储为规范数组形式的标签式数据的理想选择。更重要的是,它能够将 'machine learning' 或 'distributed systems' 等多词标签作为一个原子令牌(atomic token)进行保留,而像 splitByNonAlpha 这样基于空格的分词器则会将其拆散。
创建并填充表和索引。
复制代码CREATE TABLE job_listings(key UInt64,tags Array(String),INDEX text_idx(tags) TYPE text(tokenizer = 'array'))ENGINE = MergeTreeORDER BY key;INSERT INTO job_listings VALUES(1, ['rust', 'distributed systems', 'database']),(2, ['golang', 'machine learning', 'distributed systems']),(3, ['rust', 'machine learning', 'data engineering']),(4, ['python', 'data engineering', 'database']);
使用 hasAnyTokens 查找包含任意一组指定标签的列表。
复制代码SELECT key, tagsFROM job_listingsWHERE hasAnyTokens(tags, ['rust', 'golang']);
复制代码-- Result:-- ┌─key─┬─tags───────────────────────────────────────────────┐-- │ 1 │ ['rust','distributed systems','database'] │-- │ 2 │ ['golang','machine learning','distributed systems']│-- │ 3 │ ['rust','machine learning','data engineering']. │-- └─────┴────────────────────────────────────────────────────┘
使用 hasAllTokens 查找必须包含所有指定标签的列表。
复制代码SELECT key, tagsFROM job_listingsWHERE hasAllTokens(tags, ['machine learning', 'distributed systems']);
复制代码-- Result:-- ┌─key─┬─tags───────────────────────────────────────────────┐-- │ 2 │ ['golang','machine learning','distributed systems']│-- └─────┴────────────────────────────────────────────────────┘
由于标签数据已正确地组织为数组,因此对 hasAnyTokens 和 hasAllTokens 函数使用数组重载 (array overload) 是理所当然的选择——搜索词元 (search token) 将直接作为数组传递,无需进行预处理 (preprocessing) 或分词 (tokenization) 即可与索引元素实现精确匹配。不过需要注意的是,搜索词元的大小写问题。由于我们未对列数据进行任何预处理,只有与输入大小写完全一致的词元才能匹配。如果已知数据已全部小写,则不成问题;但即便如此,在搜索时也必须确保只使用小写标签。
在审视了上述示例后,一个可能产生疑问是:如果数据本身已经是数组形式并已完成分词 (tokenized),为何还需要将其添加到文本索引 (text index) 中?答案当然是:性能。以下示例展示了在一个拥有 1000 万行数据的相对小型表上添加文本索引所带来的显著性能提升。
复制代码-- Create tableCREATE TABLE job_listings(\`key\` UInt64,\`tags\` Array(String))ENGINE = MergeTreeORDER BY key;
复制代码-- Insert 10 million rows of random arrays of 5 stringsINSERT INTO job_listings SELECTnumber,arrayMap(x -> (['rust', 'distributed systems', 'database', 'golang', 'machine learning', 'data engineering', 'python'][(rand((number * 7) + x) % 7) + 1]), range(5))FROM numbers(10000000);10000000 rows in set. Elapsed: 13.501 sec. Processed 10.00 million rows, 80.00 MB (740.71 thousand rows/s., 5.93 MB/s.)Peak memory usage: 383.27 MiB.
复制代码-- Search without an indexSELECT count()FROM job_listingsWHERE has(tags, 'machine learning');┌─count()─┐1. │ 5373152 │ -- 5.37 million└─────────┘1 row in set. Elapsed: 0.198 sec. Processed 10.00 million rows, 1.02 GB (50.49 million rows/s., 5.13 GB/s.)Peak memory usage: 50.27 MiB.
复制代码-- Add an index using ALTER TABLEALTER TABLE job_listings(ADD INDEX text_idx tags TYPE text(tokenizer = 'array') GRANULARITY 100000000);
复制代码-- Materialize the index on existing data, this takes a while but is a one-time opALTER TABLE job_listings(MATERIALIZE INDEX text_idx)SETTINGS mutations_sync = 2;
复制代码-- Search with the index, achieving a speedup of more than 7x!SELECT count()FROM job_listingsWHERE hasAllTokens(tags, ['machine learning']);┌─count()─┐1. │ 5373152 │ -- 5.37 million└─────────┘
其他支持的功能
除了 hasAnyTokens 和 hasAllTokens 之外,文本索引还可加速其他一些函数。不过,这些函数比索引更早出现,并且不支持预处理器表达式 (preprocessor expression):
= — 精确的全值匹配;仅在配合 数组分词器 (array tokenizer) 使用时有效;
IN — 与上述 = 类似,但支持多个查询词;
LIKE / match — 用于模式匹配;它仅在配合 非字母字符分词 (splitByNonAlpha) 、N-gram 或 稀疏 N-gram (sparseGrams) 分词器使用时生效,并且前提是能够从模式中提取出完整的 token。例如, '% clickhouse %' 有效,但 '%clickhouse%' 则无效。对于像 '%word1 word2 word3%' 这样的查询,它会先使用索引搜索 word2 ,然后对匹配的行进行暴力搜索以查找模式的其余部分;
startsWith / endsWith — 与 LIKE 类似,要求能够提取完整的 token。如果函数能提取出完整单词,就能利用索引进行加速。例如, startsWith(col, word1, word2) 会先使用索引搜索 word1 ,然后对模式的其余部分进行暴力搜索。但请注意, startsWith(col, word1 word2) (注意这里的额外空格!) 将对 word1 和 word2 两个单词都使用索引;
hasToken / hasTokenOrNull — 匹配单个已预分词的 token;它不会对查询词进行分词,也不支持预处理器;
has — 匹配 Array(String) 类型列中的单个 token;
mapContains / mapContainsKey — 针对 map 键进行匹配;这要求在 mapKeys(map) 上定义索引;
mapContainsValue — 针对 map 值进行匹配;这要求在 mapValues(map) 上定义索引;
mapContainsKeyLike / mapContainsValueLike — 对 map 的键或值进行模式匹配;
map['key'] = value — 如果在 mapKeys 或 mapValues 上定义了索引,该操作将使用索引。
如需了解更多详情,请查阅 官方文档。关于支持文本索引的函数列表及其图示,请参考 此页面。需要注意的是,文本索引 (text index) 不支持否定函数(如 !=、NOT IN、NOT LIKE),因为它只记录表中实际存在的词语及其对应的 倒排列表 (postings lists)。
在了解了文本索引 (text index) 的现有功能后,接下来我们将展望其未来的发展方向。
未来展望
我们的工作远未止步。目前,图片正则表达式 (regular expression) 模式评估、优化的文本处理能力,以及 短语搜索 (phrase search) 功能。短语搜索将使索引不仅能识别 token 是否存在于某行中,还能精确地定位其出现的位置。
了解了未来的发展蓝图,接下来让我们聚焦于新版文本索引 (text index) 当前已具备的能力,以及这些能力将为 ClickHouse Cloud 用户带来哪些实际价值。
这对 ClickHouse Cloud 用户意味着什么
经过多次迭代和大量的性能优化工作,ClickHouse 中的文本索引(text index)现在无论数据存储在本地磁盘还是对象存储(object storage)上,都能提供同样出色的高性能全文搜索(full-text search)。
新的索引布局(index layout)更倾向于顺序访问模式(sequential access patterns),并允许许多谓词(predicates)直接从索引中解析,而无需从磁盘读取(indexed text columns)索引文本列。
在 ClickHouse Cloud 中,新索引得益于支撑其他大规模工作负载的同等架构优势。其中,并行副本(Parallel Replicas)能将全文查询分散到多个节点,分布式缓存(Distributed Cache)将热索引数据保留在靠近计算资源(compute)的位置,而共享对象存储则允许所有节点访问相同的索引文件,无需重新分配数据。
其结果是,全文搜索实现了与 ClickHouse Cloud 其他功能相同的扩展性:只需添加节点,查询速度就会随之提升。
敬请关注即将发布的基准测试文章,届时我们将对比新的文本索引与传统文本搜索引擎的性能,并阐释它为何能取代面向文本密集型工作负载的基于布隆过滤器(Bloom filter)的旧方法。
立即开始使用 ClickHouse Cloud,即可获得 $300 赠金。在 30 天试用期结束时,您可以选择继续使用按需付费计划,或者联系我们了解更多批量折扣信息。如需了解详情,请访问我们的定价页面。
Meetup 活动报名通知
好消息:ClickHouse Shanghai User Group 第 3 届 Meetup 火热报名中,将于 2026 年 5 月 16 日在上海市浦东新区世纪大道 1568 号中建大厦 33 层 Optiver 上海 举行,扫码免费报名:

原文链接:https://clickhouse.com/blog/clickhouse-full-text-search-object-storage