
The core problem: the “brittle” enterprise
Traditional enterprise software is deterministic; composed of a series of “If-Then” statements that break when a business condition changes. Organizations have historically filled this “logic gap” by spending thousands of human hours on manual data reconciliation and analysis.
The AI-Native prerogative is to shift from Software 1.0 (fixed logic) to Software 2.0 (learned logic). We aren’t just “plugging in” AI, like one would while implementing a chatbot. In fact, we are fundamentally rebuilding the enterprise around it so that it can:
- Reason with Uncertainty: Using probabilistic models to handle user requests..
- Scale Safely: Using a “Shielded” architecture that prevents the AI from making unvetted, high-risk moves.
- Maintain Accountability: Ensuring every “thought” of the AI is logged for audit purposes.
This blog will traverse this maze with the aid of a layered architecture that illustrates how enterprises build AI-Native applications without sacrificing compliance or security.
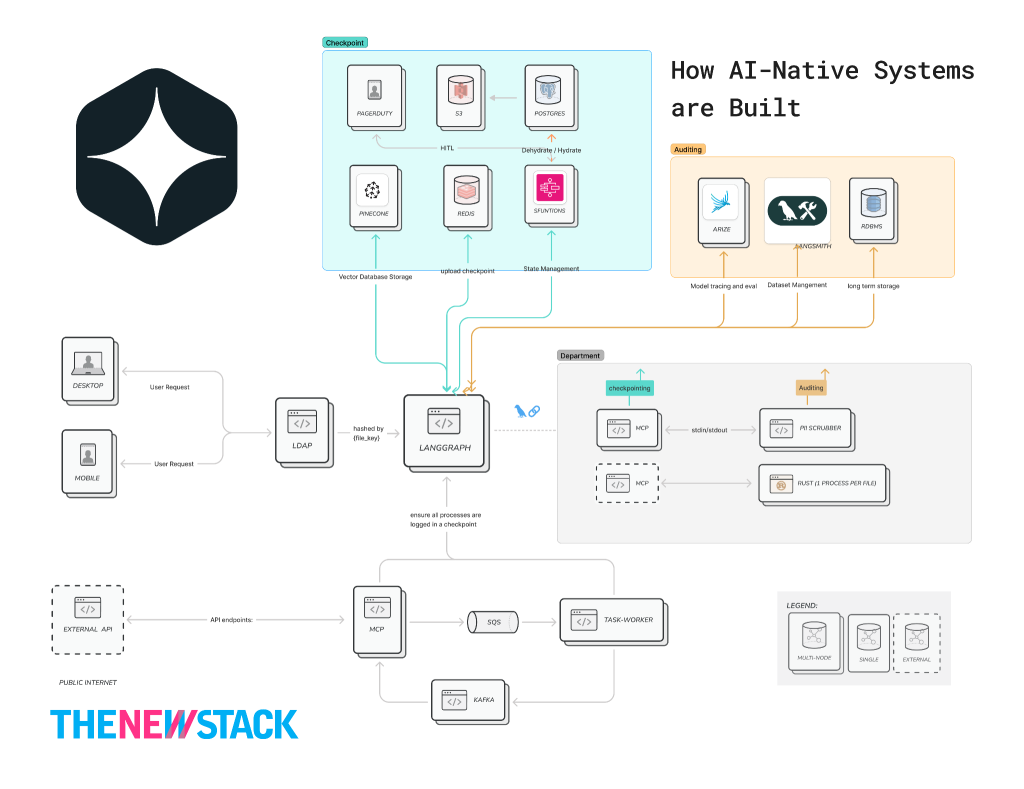
Layer 0: the deterministic shield (governance & identity): AIMS
The Goal: To ensure the AI never violates corporate policy, regardless of what the LLM “decides.”
Governance must be model-agnostic. If you switch from Claude to Gemini, your PII rules shouldn’t change. By having a “Pre-Processing” and “Post-Processing” gateway, it’s possible to ensure that sensitive data never touches third-party APIs (Inbound) and that the AI never leaks internal secrets (Outbound).
“Governance must be model-agnostic. If you switch from Claude to Gemini, your PII rules shouldn’t change.”
# The Inbound Gate
@app.post("/gateway/query")
async def inbound_shield(
request: UserRequest,
principal: Principal = Depends(verify_jwt)
):
user_id = principal.sub
user_role = await asyncio.to_thread(ldap.get_role, user_id)
clean_query = scrubber.redact(request.text)
trace_id = generate_otel_trace()
try:
await kafka.produce_and_flush(
"inbound_queries",
{
"trace_id": trace_id,
"query": clean_query,
"role": user_role,
},
timeout=5
)
except Exception as e:
logger.error("Kafka enqueue failed | trace=%s err=%s", trace_id, e)
raise HTTPException(status_code=503, detail="Queue unavailable")
return {"status": "queued", "trace_id": trace_id}
- In an enterprise, LDAP “Identity” is the most expensive asset because its enlisted to enforce Least Privilege. If the AI is asked for “CEO salary data,” the AIMS layer checks the user’s LDAP role before the request ever reaches the orchestrator. This prevents “Prompt Injection” from bypassing your security.
Layer 1: the orchestration layer
The Goal: To move from a “Stateless Chat” to a “Stateful Business Process.”
Unlike traditional apps, where logic is hard-coded, AI-native systems use an orchestration layer, like LangChain, to manage “chains” of thought.
- Decoupled Logic: The “Brain” (LLM/Model) is separated from the “Tools” (APIs, databases). This allows enterprises to swap models (e.g., moving from GPT-4 to a fine-tuned Llama-3) without rewriting the application.
To accomplish this, it must first use a Classifier: High-end models (like Claude 3.5 Opus) are expensive and slow. A Small Language Model (SLM) acts as a “Triage Nurse.” It determines if the query is simple (Deterministic script), complex (Generative AI), or requires a human. This saves up to 80% in inference costs by routing simple tasks to cheaper compute.
- The RAG Pattern (Retrieval-Augmented Generation): Prevents “hallucinations” by retrieving proprietary data from a Vector Database and feeding it into the model prompt as “context.”
- AI-native systems must remember context across multi-day workflows.
- Orchestrators use “checkpointers” to save the state of a conversation or task.
“A Small Language Model (SLM) acts as a ‘Triage Nurse.’ It determines if the query is simple, complex, or requires a human.”
To be truly audit-ready, use a Custom Checkpointer. Instead of just saving to memory, this logic ensures that every single turn is mirrored to your permanent database.
import json
import os
from langgraph.checkpoint.base import BaseCheckpointSaver
class EnterpriseAuditSaver(BaseCheckpointSaver):
def put(self, config, checkpoint, metadata):
"""
Ensure every checkpoint write is durably persisted
BEFORE allowing graph progression (fail-closed for audit integrity).
"""
thread_id = config["configurable"]["thread_id"]
checkpoint_id = checkpoint["id"]
try:
s3.put_object(
Bucket=os.getenv("AUDIT_BUCKET"),
Key=f"{thread_id}/{checkpoint_id}.json",
Body=json.dumps(checkpoint, default=str),
ServerSideEncryption="aws:kms",
)
db.execute(
"""
INSERT INTO traces (thread_id, checkpoint_id, state_blob)
VALUES (%s, %s, %s)
""",
(thread_id, checkpoint_id, json.dumps(checkpoint, default=str))
)
except Exception as e:
logger.exception(
"Audit write failed | thread=%s checkpoint=%s error=%s",
thread_id,
checkpoint_id,
str(e)
)
raise
return super().put(config, checkpoint, metadata)
# Compile graph
# checkpointer = EnterpriseAuditSaver()
# app = workflow.compile(checkpointer=checkpointer)
- Tooling/Function Calling: Orchestrators are granted “tools” (APIs or internal databases). The orchestrator ensures the MCP calls these tools using strictly defined schemas to prevent “hallucinated” API calls.
- Traditional AI “chains” are one-way streets. If a tool fails (e.g., the SQL database is down), a simple chain crashes. LangGraph allows the system to “reason about the error.” It can catch the exception, review the error log, and decide whether to try a different tool or notify a human.
- Human-in-the-Loop (HITL): Best practices dictate that for high-stakes decisions, like credit approvals, the orchestrator must pause the agent and wait for a human “OK” before proceeding.
import os
COMPLEXITY_THRESHOLD = int(os.getenv("COMPLEXITY_THRESHOLD", "7"))
CONFIDENCE_THRESHOLD = float(os.getenv("CONFIDENCE_THRESHOLD", "0.95"))
MODEL_REGISTRY = {
"high": "claude-sonnet-4-5",
"low": "gpt-4o-mini"
}
def estimate_confidence(response):
"""
Confidence must be derived, not assumed.
Options in production:
- logprob aggregation
- self-critique model
- external evaluator model
"""
return getattr(response, "logprob_score", 0.8)
def call_model(state: GraphState):
if state["complexity"] > COMPLEXITY_THRESHOLD:
model = MODEL_REGISTRY["high"]
else:
model = MODEL_REGISTRY["low"]
response = llm.invoke(state["prompt"], model=model)
confidence = estimate_confidence(response)
if confidence < CONFIDENCE_THRESHOLD:
return "trigger_dehydration"
return "finalize_result”
# Define graph
workflow = StateGraph(GraphState)
workflow.add_node("reasoning", call_model)
workflow.add_edge("reasoning", "tools")
Layer 2: the persistence spine
The Goal: To make the AI-native system “asynchronous and durable.”
If your AI orchestrator container crashes mid-thought, the message stays in the Kafka Topic. When the container restarts, it picks up exactly where it left off. This “Nervous System” provides Zero Data Loss.
- Event-Driven Triggering: Systems are no longer just “prompt-response.” They use tools to automatically trigger AI agents when a database record changes or an event occurs.
- AI inference is costly. If a process needs human approval, you don’t want a container sitting in memory for 4 hours waiting for a click. Recommendation: Implement a Hydration/ Dehydration Mechanism.
- Dehydration serializes the “Brain State” and moves it to cheap storage (RDBMS/S3).
- Step Functions handles the “Sleep” logic.
- Rehydration wakes the system up only when needed, minimizing cloud costs and maximizing resource availability.
import json
import os
import re
import boto3
s3_client = boto3.client("s3")
THREAD_ID_PATTERN = re.compile(r"[A-Za-z0-9_-]{1,64}")
def _validate_thread_id(thread_id: str) -> str:
if not isinstance(thread_id, str) or not THREAD_ID_PATTERN.fullmatch(thread_id):
raise ValueError(f"Invalid thread_id: {thread_id!r}")
return thread_id
def dehydrate_to_s3(state, task_token, thread_id):
"""
Serializes the AI state and pauses execution.
Security:
- Validates thread_id to prevent path traversal / tenant escape
- Encrypts state at rest
"""
thread_id = _validate_thread_id(thread_id)
bucket = os.environ["AI_STATE_BUCKET"]
checkpoint_key = f"checkpoints/{thread_id}/state.json"
try:
s3_client.put_object(
Bucket=bucket,
Key=checkpoint_key,
Body=json.dumps(state, default=str),
ServerSideEncryption="aws:kms",
)
# db.update_metadata(thread_id, status="WAITING_FOR_HUMAN", #s3_ptr=checkpoint_key)
print(f"Pausing workflow. Task Token: {task_token}")
except Exception as e:
logger.exception("Dehydration failed | thread=%s err=%s", thread_id, e)
raise
return {"status": "DEHYDRATED", "s3_ptr": checkpoint_key}
Why this “split” strategy (S3 + RDBMS)?
| Storage Type | Purpose | Reason |
| RDBMS / DynamoDB | Metadata & Indexing | Used by the Dashboard to show a list of “Pending Tasks.” It stores the thread_id, timestamp, and a pointer. It is fast for queries like “Show me all tasks waiting for HR approval.” |
| Amazon S3 | Large State Blobs | LangGraph states can get huge (chat history, retrieved docs). RDBMS databases choke on large JSON blobs over time. S3 handles 10MB+ states for pennies and keeps them for regulatory audit. |
When the HITL interacts and Clicks “Approve,” the app calls this Lambda to wake the AI back up, or “Rehydrate.”
import json
import os
import re
import boto3
s3_client = boto3.client("s3")
sfn_client = boto3.client("stepfunctions")
THREAD_ID_PATTERN = re.compile(r"[A-Za-z0-9_-]{1,64}")
def _validate_thread_id(thread_id: str) -> str:
if not isinstance(thread_id, str) or not THREAD_ID_PATTERN.fullmatch(thread_id):
raise ValueError(f"Invalid thread_id: {thread_id!r}")
return thread_id
def rehydrate_and_resume(event, context):
"""
Triggered by Human UI (via authenticated API).
Security:
- Validates inputs
- Authorizes approver
- Prevents token replay
- Uses encrypted state
"""
try:
task_token = event["task_token"]
human_input = event["human_decision"]
thread_id = _validate_thread_id(event["thread_id"])
approver_id = event["approver_id"]
except KeyError as e:
return {"statusCode": 400, "body": f"Missing field: {e}"}
except ValueError as e:
return {"statusCode": 400, "body": str(e)}
if not authz.can_approve(approver_id, thread_id):
logger.warning(
"Unauthorized approval attempt | approver=%s thread=%s",
approver_id,
thread_id,
)
return {"statusCode": 403, "body": "Not authorized"}
if not token_store.matches(thread_id, task_token):
return {"statusCode": 409, "body": "Stale or invalid task token"}
bucket = os.environ["AI_STATE_BUCKET"]
key = f"checkpoints/{thread_id}/state.json"
try:
obj = s3_client.get_object(Bucket=bucket, Key=key)
frozen_state = json.loads(obj["Body"].read())
frozen_state.setdefault("messages", []).append(
{"role": "human", "content": human_input}
)
frozen_state["status"] = "RESUMED"
frozen_state["approved_by"] = approver_id
token_store.invalidate(thread_id, task_token)
sfn_client.send_task_success(
taskToken=task_token,
output=json.dumps(frozen_state, default=str),
)
except Exception as e:
logger.exception("Rehydration failed | thread=%s err=%s", thread_id, e)
return {"statusCode": 500, "body": "Rehydration failed"}
return {"statusCode": 200, "body": "AI rehydrated and processing"}
- LangGraph hits a “Human Required” node.
- Worker saves JSON to S3 and sends the task_token to the dashboard.
- Step Functions freezes the workflow.
- Human reviews and submits an answer.
- API sends the token back; Step Functions rehydrates the S3 data into a new worker.
- AI resumes with the human’s answer as part of its “memory.”
Layer 3: auditing & observability
The Goal: To turn the “Black Box” of AI into a transparent business metric.
- I recommend using Arize Phoenix because it acts as the “Model Judge.” In practice, it does this by using an LLM to evaluate another LLM’s performance. It looks for “Hallucination Scores,” or evidence that the AI is starting to make things up. The instant that occurs, Phoenix flags it before the user sees it.
- LangSmith helps connect the dots. It allows IT departments to say: “This specific response took 4 seconds, cost $0.05, and was approved by Human Agent X.” This is the audit trail required for SOC2 and GDPR compliance.
While standard LangGraph checkpointers save state for recovery, an audit-ready checkpointer mirrors that state to S3 or RDS with rich metadata (who, when, why) at every “super-step.”
from typing import Annotated, TypedDict, List
from operator import add
class AuditEntry(TypedDict):
node: str
thought: str
timestamp: str
metadata: dict
class AgentState(TypedDict):
# 'add' ensures we append to the history rather than overwriting
messages: Annotated[List[dict], add]
audit_log: Annotated[List[AuditEntry], add]
internal_monologue: List[str] # Current thought process
status: str
The LangGraph implementation with audit nodes
Add a dedicated “Observer” pattern where nodes report their “thoughts” before and after execution:
import datetime
from langgraph.graph import StateGraph, START, END
def reasoning_node(state: AgentState):
# Logic: The AI 'thinks' before acting
thought = "I need to check the inventory levels before approving the CEO's request."
# Audit log entry
audit = {
"node": "reasoning_node",
"thought": thought,
"timestamp": datetime.datetime.now(datetime.timezone.utc).isoformat(),
"metadata": {"model": "claude-3-5-sonnet", "tokens": 450}
}
# Perform the actual logic...
result = "Searching DB..."
return {
"internal_monologue": [thought],
"audit_log": [audit],
"messages": [{"role": "assistant", "content": result}]
}
# The 'Audit Hook' Node
def audit_persistence_node(state: AgentState):
"""
This node acts as a gateway to long-term storage.
It 'dehydrates' the current audit trail to S3.
"""
latest_audit = state["audit_log"][-1]
# In practice, call your S3/RDS logic here
# s3.upload_json(latest_audit, key=f"audits/{trace_id}/{step}.json")
print(f"[AUDIT LOGGED]: Node {latest_audit['node']} completed.")
return state
LangSmith is natively integrated into LangChain. I recommend using Custom Annotations to tag the chain of thought so it’s searchable.
from langsmith import traceable
from langchain_openai import ChatOpenAI
from config import settings # your centralized config
@traceable(
run_type="chain",
name="Inventory_Reasoning_Step",
metadata={
"department": "logistics",
"priority": "high"
}
)
def reasoning_node(state):
"""
Production-safe reasoning node:
- No environment mutation
- No chain-of-thought leakage
- Structured reasoning context instead
"""
reasoning_context = {
"intent": "inventory_analysis",
"data_source": "s3+rds",
"request_origin": "ceo_query"
}
data = state.get("data", "")
if not isinstance(data, str):
data = str(data)
safe_data = data[:5000] # prevent excessive token usage
llm = ChatOpenAI(model="gpt-4o")
response = llm.invoke(
f"Analyze the following structured data:\n{safe_data}"
)
return {
"messages": [response],
"reasoning_context": reasoning_context
}
Arize Phoenix acts as your Automated Compliance Officer. It traces and runs “Judgments” to see if the AI hallucinated.
import phoenix as px
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# 1. Launch Phoenix (local or cloud)
session = px.launch_app()
# 2. Register the OTel tracer (This is your OTel Spine)
tracer_provider = register(
project_name="AI-Native-Enterprise",
endpoint="http://localhost:6006/v1/traces" # Your Phoenix Collector
)
# 3. Instrument LangChain/LangGraph
# Every node execution now streams to Phoenix automatically
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
# 4. Example: LLM-as-a-Judge (Hallucination Detection)
from phoenix.evals import HallucinationEvaluator, OpenAIModel, run_evals
# We run this on a schedule or after a HITL rehydration event
evaluator = HallucinationEvaluator(model=OpenAIModel(model="gpt-4o"))
results = run_evals(
dataframe=px.active_session().get_spans_dataframe(),
evaluators=[evaluator],
provide_explanation=True
)
Organizational impact
Implementation shifts the workforce from Task Performers to AI-Native System Governors.
- Data Science builds the “Brains” (Models).
- Engineering builds the “Nervous System”.
- Business Units manage the “Exceptions” (HITL).
The result is an organization that operates at the speed of AI for 95% of its tasks, while remaining 100% compliant and human-verified for the high-stakes 5%.
The post How AI-native systems are built