
At NetEase Games, we learned a hard lesson about large language model (LLM) inference in production: elastic compute is only useful if data can move just as fast.
“Elastic compute is only useful if data can move just as fast.”
On paper, serverless GPU infrastructure looked like a good fit for inference workloads. Game traffic is bursty, peaks differ by title and time of day, and reserving GPU capacity for every possible spike is expensive. But once we started scaling LLM services across regions, a different bottleneck emerged. The real problem was not scheduling containers. It was loading model data.
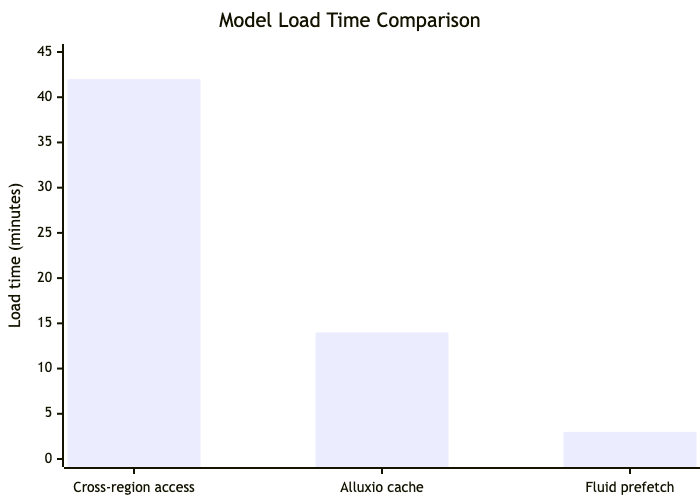
For 70B-class models, pulling hundreds of gigabytes of weights from remote storage into inference nodes could take tens of minutes. That erased the value of autoscaling. In one representative workload, model load time was reduced from 42 minutes with cross-region direct storage access to 14 minutes with a traditional Alluxio-based cache and then to 3 minutes after we enabled Fluid’s prefetching workflow. That difference turned serverless inference from an architectural idea into something we could actually operate.
The Day 2 problem: Cold starts, shared models, and fragmented GPU capacity
Our AI platform, Tmax, runs on Kubernetes and supports the full ML lifecycle, from notebook-based development to training and inference deployment. As LLM usage increased across game-related scenarios — including intelligent NPCs, content generation, and internal AI services — three operational problems became tightly coupled.
First, GPU resources were scarce and heterogeneous. Different workloads require different card types, memory sizes, and scaling patterns. Keeping enough GPU capacity online for peak demand across every team was inefficient.
Second, inference traffic was not uniform. Some titles peaked in the evening, others during the day. Some workloads were latency-sensitive online inference; others were batch jobs or fine-tuning tasks. Static provisioning drove utilization down and waste up.
Third, serverless cold starts were dominated by model loading. Even when computing resources became available quickly, the model’s data path remained slow. The result was an expensive system that still could not respond to traffic spikes in time.
This is where “Day 2” operations got interesting. The question was no longer how to deploy inference services. It was how to keep model access fast, consistent, and manageable across regions and namespaces over time.
Why we didn’t just run Alluxio directly
What we needed was a Kubernetes-native way to define datasets, prewarm them, mount them into workloads, and share them safely across namespaces. We also needed the runtime layer to scale in step with application behavior.
That higher-level abstraction was the main reason for choosing Fluid, a Cloud Native Computing Foundation (CNCF) incubating project. With Fluid, the operational unit is not just a cache cluster. It’s a dataset and runtime. This configuration maps better to how platform teams actually manage model-serving infrastructure.
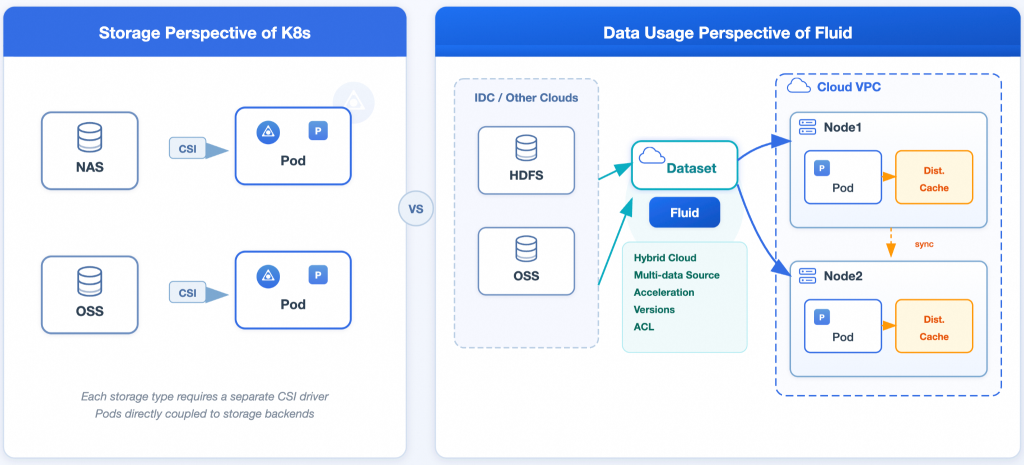
Fluid: Adding operational control to Alluxio
| Dimension | Challenges With Running Alluxio Directly | What Fluid Added |
| Integration with Kubernetes | Alluxio master and worker clusters had to be deployed and managed separately, with limited alignment to Kubernetes-native lifecycle and scheduling behavior. | Fluid automated runtime deployment and lifecycle management, supported cache elasticity through mechanisms such as HPA/KEDA, and made it easier to align compute placement with cached data through data-aware scheduling. |
| LLM inference-specific optimization | General-purpose caching improved access times, but loading large models still required custom warmup logic and additional operational work. | Fluid provided prefetch workflows for scheduled, event-driven, and proactive warm-up. It also lets us optimize for framework-specific access behavior, including vLLM and SGLang-style model-loading patterns, and scale the cache down again after deployment when appropriate. |
| Data abstraction and runtime decoupling | A direct deployment model tied operations more closely to a single cache implementation, making long-term evolution harder. | Fluid separated the dataset abstraction from the runtime layer. That allowed us to maintain a stable operational model while retaining the option to switch runtimes over time, such as Alluxio, JindoCache, or JuiceFS. |
| Isolation and sharing across teams | Multi-team sharing required more manual namespace, quota, and configuration design, especially when common base models had to be reused safely. | Fluid supported dataset-level logical isolation and cross-namespace sharing, with access control aligned to native Kubernetes mechanisms. |
| Support for heterogeneous compute environments | Deploying and managing the same data access model across environments, such as serverless containers, was more difficult and usually required additional integration work. | Fluid supported both CSI- and Sidecar-based access patterns. Webhook-based Sidecar injection reduced the amount of application-side change needed to use the same model-loading path across environments. |
Fluid also made a few common patterns easier for us to:
- Prefetch before startup so inference Pods do not pay the full cold-start penalty at runtime.
- Schedule scale-up and warm-up for workloads with predictable traffic windows.
- Cross-namespace models share a common base; they do not have to be repeatedly cached by each team.
The last point mattered more than we expected. In a multi-tenant platform, repeated caching of the same model wastes memory and creates version-management overhead. Fluid lets us maintain shared models in a single namespace and expose them to application teams via references rather than duplicate runtime stacks.
What changed in production
The result was not a small tuning improvement. It changed whether elastic inference was practical for us.
In an earlier benchmark path, model load time dropped from 42 minutes with cross-region direct access to 14 minutes with a conventional cache layer, and then to 3 minutes after enabling Fluid-based prefetching. After further tuning in production, the startup time for two model inference services was reduced to about one minute and, in some cases, even under 30 seconds.
The significant reduction in latency led to a corresponding reduction in cost, allowing us to scale GPU resources more aggressively during quiet periods.
The cache-sharing model also reduced waste. Instead of caching the same foundation model separately for each namespace, we could warm it once and let multiple services consume it. That lowered cache memory overhead and simplified operations for platform teams.
Just as important was the distributed cache that helped absorb startup bursts. When many inference Pods were launched together, the platform no longer pushed all of that pressure directly onto the backend storage path.
A useful way to frame the choice
For us, the comparison was not really “Fluid versus Alluxio” as competing products. It was a choice between solving a narrow problem and solving the operational one.
If the requirement is simply to put a cache in front of remote storage, running Alluxio directly may be enough. If the requirement is to operate LLM inference on Kubernetes over time — with prefetching, sharing, autoscaling, and multi-tenant controls — then the higher-level data orchestration model matters.
“The issue was never just where the model files lived. The challenge was making them available quickly, predictably, and affordably for production inference.”
That was the difference in our case. The issue was never just where the model files lived. The challenge was making them available quickly, predictably, and affordably for production inference.
The post How NetEase Games cut LLM cold starts from 42 minutes to 30 seconds