
“Just use Postgres” is the logical path for a startup figuring out product-market fit. But Sprig – an AI-powered product research platform – hit that fit much sooner than expected. And the sheer scale of the resulting data (over 1.3T events and 75 B attributes from 15B visitors) maxed out Postgres much sooner than expected.
In March, at Monster Scale Summit, Brendan Cox, Senior Staff Engineer at Sprig, walked through the full journey: why their seemingly simple platform hit database limits so fast, the various approaches they tried, and how their small engineering team worked through these challenges. Watch the complete talk, or read the highlights below.
The complexity behind Sprig’s surface-level simplicity
At the surface, Sprig’s core product seems relatively straightforward. Customers install the Sprig SDK into their mobile apps or websites to track user actions and attributes. When a user’s behavior matches the set criteria, Sprig triggers a targeted in-product survey. Because these surveys collect so much feedback, Sprig then uses AI to process and report findings for product researchers.
Under the hood, a high-speed data engine is required to evaluate all this user behavior in real-time. “What we built actually has a lot in common with analytics, ad tech, or recommendation systems,” explained Brendan. “That is, it’s a low-latency, compute and data-heavy system that must make decisions up to thousands of times per second.”
For a small startup, Sprig manages an impressive volume of data. At any given time, the platform tracks 15 billion distinct visitors across multiple devices. To understand those visitors, the backend maintains 75 billion user attributes and 20 billion different event counters, having processed over 1.3 trillion events to date (as of February 2026).
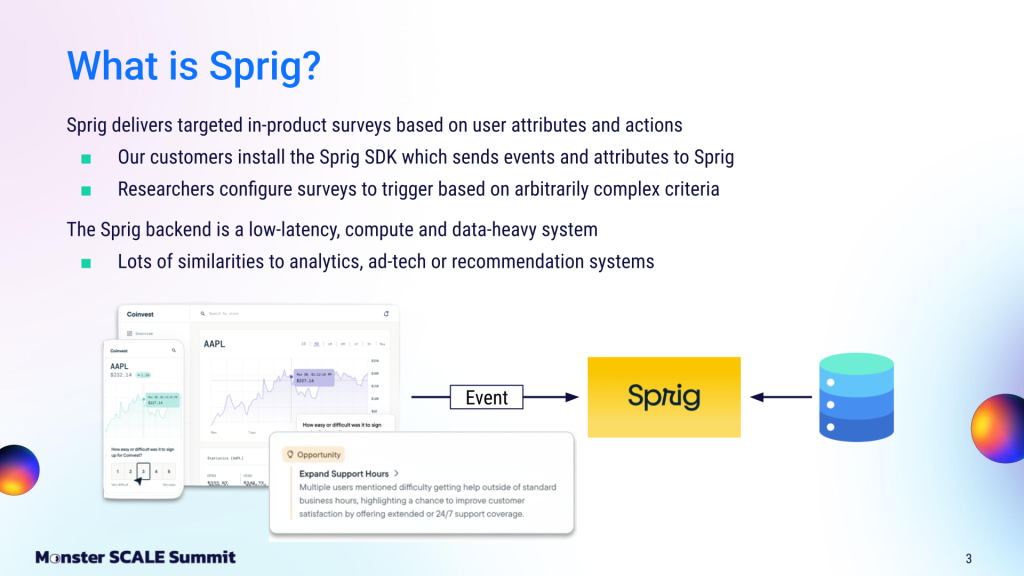
Sprig’s backend systems process 20,000-40,000 events and attributes per second. For each incoming event, the system must evaluate complex trigger criteria and decide whether to display a survey within milliseconds.
Phase 1: Just use Postgres
In the beginning, Sprig followed the classic startup playbook: they built their initial system on PostgreSQL (they opted for the Amazon Aurora flavor). As Brendan noted, “This is exactly where every startup should start off. Basically, just do the simple thing and get product market fit”.
Sprig found that product-market fit remarkably fast. However, as larger and larger customers came onto the system, they hit the limits of Postgres. Per Brendan, “We had high write throughput, which was saturating a single writer instance in Aurora. We also reached the maximum number of reader instances and the maximum instance size available to us at the time in AWS. This was incredibly expensive for our company. It was absolutely imperative to get off this system as soon as possible and onto something new.”
Phase 2: Add ClickHouse and Redis
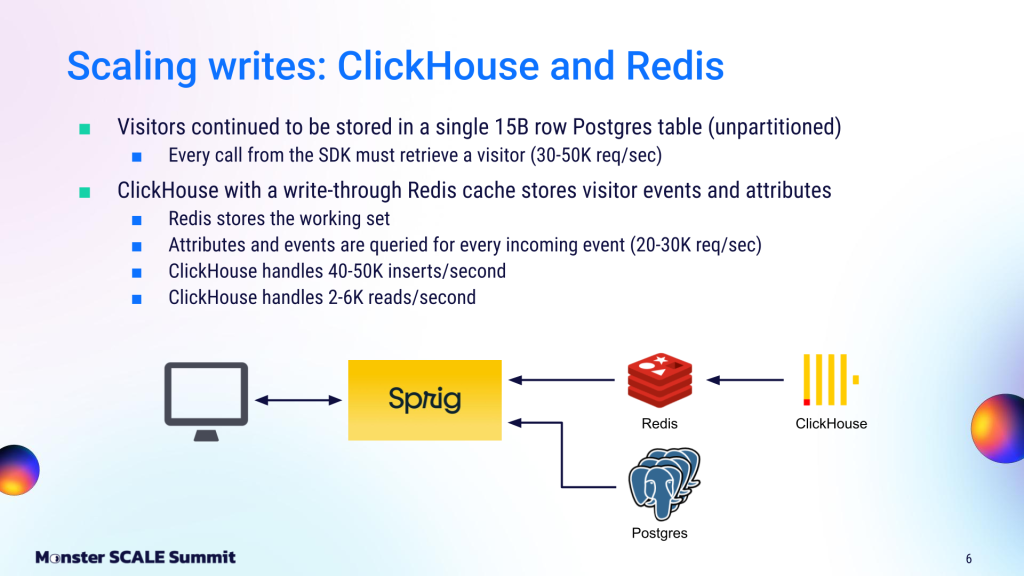
So the team came up with a new approach. They decided to keep only visitor data on Postgres, then offload “events and attributes” traffic to a completely different setup: a ClickHouse database sitting behind a Redis write-through cache.
The visitor data was stored in a large, unpartitioned Postgres table (they needed to query it across multiple columns, which required several indexes). Every SDK call had to retrieve a visitor record, which triggered 30,000-50,000 requests per second to the Postgres instance.
The events and attributes, however, had much higher throughput and volume. They selected ClickHouse for this data based on past positive experiences. However, since ClickHouse isn’t ideal for high-throughput point queries, they placed Redis in front of it as a write-through cache.
Redis served the full working set required to process incoming events and attribute requests. It handled the bulk of request traffic, while ClickHouse operated behind it as the system of record. ClickHouse absorbed 40,000 – 50,000 inserts per second, while serving a more modest 2,000 – 6,000 reads per second.
However, even that read volume is higher than what ClickHouse, as an analytical database, is really designed for. So the team worked on various optimizations and configuration tweaks. Specifically, they hashed visitor IDs to ensure lookups hit only a single partition, and shrank the ClickHouse granule size below the standard 8,200 rows to minimize disk I/O. They also strictly minimized threading; by setting max threads to 1 and using the `pread` file system read method, they prevented threads from constantly context-switching and fighting for CPU during heavy lookups.
Where Postgres + Redis + Clickhouse fell short
Despite those read optimizations, scaling writes remained a challenge. On the Postgres side, storing 15B rows in a single unpartitioned table became increasingly problematic. The working set no longer fit in memory, leading to frequent disk reads and skyrocketing AWS IOPS costs.
Tail latencies were already worsening (P99s around 50ms). And since Postgres was running in a shared environment, even a single inefficient query or missing index could further degrade performance.
Meanwhile, the ClickHouse + Redis setup was also showing signs of strain. Despite extensive optimization, P90 and P99 latencies remained high (P99s around 50ms), and the system experienced periodic brownouts under shifting access patterns, batch jobs, or changing workloads.
On top of this, growth projections predicted a 3–5X increase in write throughput.
The real wake-up call came when they met with AWS Postgres experts to try to resolve the issue. “This might be the largest unpartitioned Postgres table I’ve seen,” one AWS expert told the Sprig team.
“This might be the largest unpartitioned Postgres table I’ve seen.”
That wasn’t exactly what they wanted to hear. “We knew that we were flying pretty high with this, but we didn’t realize that we were flying higher than anyone else and didn’t know how close to the sun we were getting,” Brendan recalled. “We didn’t know when this would all come crashing down.”
Finding the right database fit
Looking to find a better approach before it all came crashing down, the team ran a systematic evaluation across four options:
- DynamoDB: Dismissed on cost. At Sprig’s event and attribute volume, DynamoDB’s read/write capacity unit pricing would have been prohibitive. Prior painful write reliability issues on the team also ruled it out.
- DataStax Astra: Dismissed after benchmarking showed higher latencies and uncertain scaling behavior. Also, the IBM acquisition added a level of risk they weren’t comfortable with.
- Self-hosted Cassandra on Kubernetes: Dismissed on two grounds: immediate unacceptable tail latencies in testing, and the operational overhead of running a large Java-based distributed database with a two-person team.
- Self-hosted ScyllaDB on Kubernetes with EBS volumes: Technically this worked, even though it’s not a recommended configuration. However, the team ruled it out because they didn’t want to own another distributed database operationally.

But they liked ScyllaDB, particularly its low latency at Sprig’s scale. Brendan explained, “90%-95% of our reads are cached, so ScyllaDB, with a fast row cache, is very good for our workloads.”
Also important: ScyllaDB offered native, highly performant Materialized Views. Sprig needed them to index their massive visitor table across multiple columns. While Cassandra’s Materialized Views are “much maligned in the Cassandra community and not really officially supported anymore,” ScyllaDB’s Materialized Views were “rock solid” in Sprig’s tests.
The deciding factor, though, was the fully-managed deployment model. “ScyllaDB Cloud allowed our engineers to focus on our core competency of building systems and supporting our product,” Brendan stated. “The great thing is that we have database experts, the ones who actually built the system, to run the database for us.”
Phase 3: Moving to ScyllaDB Cloud
The migration itself was made easier by Sprig’s existing architecture:
- Live writes via Kafka connector. All data flowing into ClickHouse already passed through Kafka. The team wrote a Kafka connector to simultaneously write that data to ScyllaDB, running both systems in parallel.
- Historical backfill via bulk loader. A custom bulk loader pulled existing records from ClickHouse and wrote them into ScyllaDB, running concurrently with the Kafka connector.
- Race condition handling. With two write paths running simultaneously, they needed a conflict resolution strategy. They used last-write-wins, with the updated_at field on each record as the authoritative timestamp.
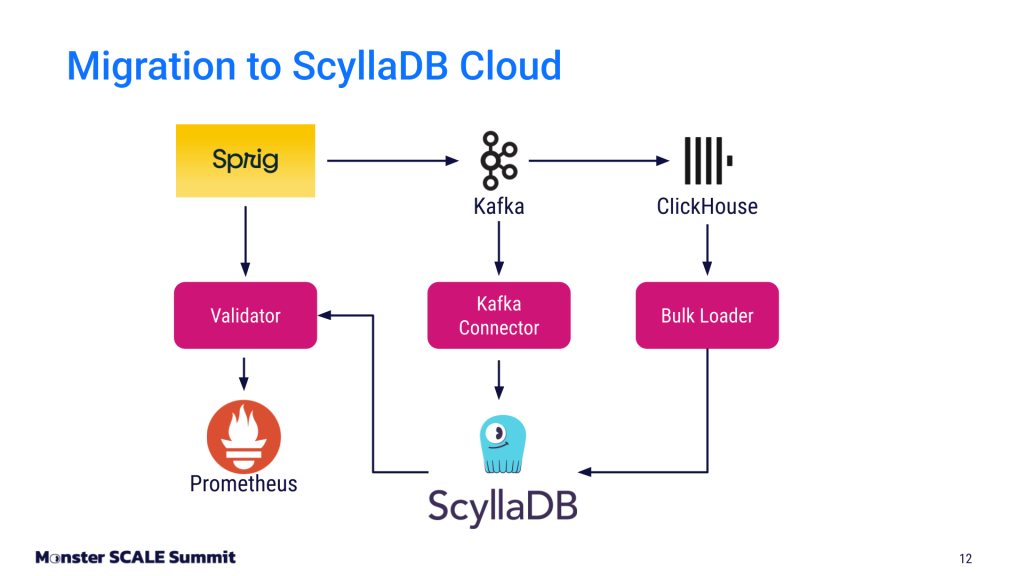
To gain confidence in the migration, the team built a validation layer that dual-read from both the ClickHouse/Redis cluster and ScyllaDB simultaneously. They compared values between the two systems, piping agreements, and differences into Prometheus. “We logged differences to help us dive into data inconsistencies and really debug where things were going,” Brendan explained.
Once they hit roughly 99.99% agreeability between the two systems, they flipped the switch and started reading and writing to ScyllaDB.
“It was not exciting…until we looked at our latency graphs.”

Explaining the ScyllaDB vs Redis latency results, Brendan said: “We see about 4X less latency in reading from ScyllaDB for our attributes workload compared to Redis. We’re reading a fair amount of data from Redis, and ScyllaDB held up very well for this. Overall, our mean latencies coming out of ScyllaDB are about 500 microseconds, and our P90 latencies are about 1-2 milliseconds. That’s 4-8X better than what we were seeing in our in our Redis setup.”
“We see about 4X less latency in reading from ScyllaDB for our attributes workload compared to Redis. We’re reading a fair amount of data from Redis, and ScyllaDB held up very well for this.”
Beyond the predictable low latencies, there are fewer alarms, and the team is no longer constantly tweaking the database. Most importantly for the growing business, they can easily scale out the cluster as needed as they bring on new customers and new workloads.
Next on the team’s TODO list:
- Switching from Leveled Compaction to an Incremental Compaction strategy, which offers better write amplification properties and is a good fit for cached reads.
- Using Workload Prioritization to ensure that heavy weekend batch jobs never impact real-time production reads.
- Moving additional tables off of Postgres and over to ScyllaDB.
Brendan summed up the project: “This migration has been a roaring success for our team, not just in terms of database performance, but also cost efficiency and scalability. It has greatly reduced the operational complexity of our infrastructure.”
The post ScyllaDB cut Sprig’s read latency 4X after Redis and ClickHouse hit a wall