
Every frontier model in 2026 advertises a context window of at least a million tokens, but almost none of them are actually great at making use of all of that information. On MRCR v2, the multi-reference retrieval benchmark labs report, the best model is GPT-5.5, which scores 74.0%. Others like Claude Opus 4.7 at 32.2% are far behind.
At this point, a million tokens seems to be the maximum for the context window that the major frontier labs are offering. One major reason for the million-token max is the same one that has shaped every transformer-based model since 2017: Attention cost scales quadratically with context length, so doubling the input quadruples the work. Essentially, RAG, agentic decomposition, hybrid model architectures, and every other workaround the industry has built are ways of making tradeoffs to get around this.
Subquadratic, a Miami-based startup, launched its first model on Tuesday and claims it can get around all of this, now offering a model that can handle a token window of 12 million tokens. What’s more, the company says it plans to offer a model with a 50-million-context window soon.
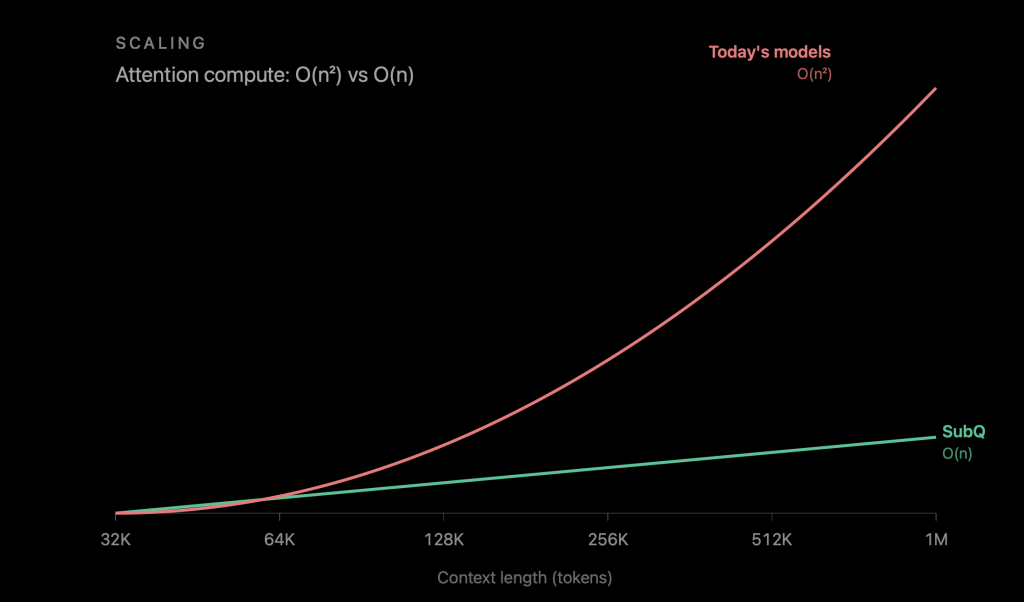
The company, which has 11 Ph.D. researchers on staff, argues that its architecture, called Subquadratic Selective Attention (SSA), scales linearly in both compute and memory with respect to context length. The company says it runs 52 times faster than dense attention at a million tokens, hits 92.1% on needle-in-a-haystack retrieval at 12 million tokens — a context length no frontier model currently gets close to — and scores 83 on MRCR v2, beating OpenAI by nine points.
The company says its Subquadratic Selective Attention architecture runs 52 times faster than dense attention at a million tokens, hits 92.1% on needle-in-a-haystack retrieval at 12 million tokens, and scores 83 on MRCR v2, beating OpenAI by nine points.
Those are large claims, and Subquadratic isn’t the first to try to tackle this problem. The benchmarks the company is releasing are impressive, including a 82.4% score on SWE-bench, which bests Anthropic’s last model, Opus 4.6, which scored 81.42% and Google’s Gemini 3.1 Pro at 80.6%. And it’s doing all of this at a significantly lower cost.
Subquadratic is making this model available through an API — which will feature a 12-million-token context window — as well as a coding agent (SubQ Code) and a deep research tool (SubQ Search).
What came before
The quadratic cost of attention is obviously not a new problem, and SSA is not the first attempt to solve it. The research line goes back nearly to the original transformer paper, and the overall pattern has remained consistent. Every approach has traded one necessary property to gain another, and none have been able to replace dense attention at the frontier scale.
Every approach has traded one necessary property to gain another, and none have been able to replace dense attention at the frontier scale.
Among the different approaches is, for example, fixed-pattern sparse attention. In models like Longformer, it achieves linear scaling by letting each token attend only to a sliding window. It works when relevant information sits nearby and breaks when it does not.
State-space models like Mamba, Mamba-2, RWKV, RetNet replace the all-pairs comparison with a recurrent state that compresses everything seen so far. The compression is lossy, however. Nvidia’s study at 8B scale found pure Mamba-2 lagged transformers on MMLU and phonebook lookup, with the gap closing only when attention was added back.
Hybrid architectures, as seen in Jamba, Kimi Linear, Qwen3-Next, and Nvidia’s Nemotron v3, are the pragmatic answer to this. They keep most layers efficient and retain a few dense attention layers for retrieval. But the economics are less favorable than they look. A hybrid that is three times cheaper at 32K tokens remains three times cheaper at 10M tokens, because the dense layers it retains still do O(n²) work.
The most recent entries went in a different direction. Rather than trying to fix the pattern or compress the state, they learn which positions to attend to.
DeepSeek’s Native Sparse Attention won the ACL 2025 best paper award, for example. Its successor, DeepSeek Sparse Attention (DSA), is shipping in DeepSeek V3.2-Exp. DSA’s lightning indexer routes attention to a small subset of selected keys, and the attention over those keys is genuinely sparse. The indexer that picks them, however, has to score every query against every key, meaning the selection step is itself quadratic.
SubQuadratic CTO Alex Whedon tells The New Stack, “Sparse attention basically means instead of doing what transformers do, which is if you have 1,000 words, you look at every possible relationship between all 1,000 words, which is 1,000 squared combinations. You realize that only a portion of those actually matter and you only process the portion that matter.”
What SSA says it does differently
SSA’s pitch is that it does what DSA tried to do without the indexer trap. Selection is content-dependent. For any given query, the model picks which positions matter based on what the query and keys actually contain — and most importantly, the selection mechanism itself does not go quadratic.
“For prompt A, words one and six are going to be important to each other,” Whedon says. “For prompt B, maybe it’s words two and three. It’s different for every single input.”
According to Whedon, hybrids deliver “a scalar benefit,” but a pure subquadratic mechanism delivers a scaling-law advantage. SubQ’s reported 7.2× speedup at 128K and 52.2× at 1M in its benchmarks.
The benchmarks
On RULER at 128K, SubQ scores 97.1 against Opus 4.6’s 94.8. On MRCR v2, the gap to the rest of the frontier is wider than the gap between the rest of the frontier and itself.
On SWE-Bench Verified, SubQ reports 82.4%, edging out Opus 4.6’s 81.4%, and Gemini 3.1 Pro’s 80.6%. At 12 million tokens, where no frontier model operates, SubQ holds 92.1% on a needle-in-a-haystack benchmark.
There are some caveats. Each model was run only once, according to the technical paper, due to their high inference cost. The SWE-Bench margin is, as the paper acknowledges, “harness as much as model.” And the SubQ model is, by Whedon’s own description, “way smaller than the big labs.”
What Subquadratic is shipping now
The company is launching two products in beta: an API that exposes the full 12M-token window and SubQ Code, a CLI agent built on the same model. Both run on neoclouds rather than the major hyperscalers — “they’re very expensive,” CEO Justin Dangel says.
The company is not open-sourcing weights but plans to offer training tools for enterprises to do their own post-training. The 50-million-token context window target is set for Q4.
There is a bit of a cautionary tale here, though. Magic.dev announced a 100M-token context-window model in August 2024, with a claimed 1000× efficiency advantage. It raised over $500 million on its strength. As of early 2026, there is no public evidence of LTM-2-mini being used outside Magic.
Funding
Subquadratic has raised $29 million to date at a $500 million valuation from investors including former SoftBank Vision Fund partner Javier Villamizar and Tinder co-founder Justin Mateen. The company was previously called Aldea and worked on speech models before pivoting. The technical case is real. The category’s track record is the rest of the story.
The post The context window has been shattered: Subquadratic debuts a 12-million-token window