Uber 工程师利用自动代码转换和编排工具,在他们的一个 Java 单体存储库中将超过 75000 个测试类和 125 万多行代码从 JUnit 4 迁移到了 JUnit 5。此次迁移的动因在于需要采用一个可扩展性更强的现代化测试框架,并减少与处于维护模式的遗留系统相关的技术债务。
JUnit 4 自 2021 年起已经进入维护模式,而 JUnit 5 则引入了基于 JUnit Platform 的模块化架构,支持 Jupiter 引擎,并改进了参数化测试功能。对于 Uber 而言,继续使用 JUnit 4 会限制对新功能的使用,因此尽管规模和基础设施限制带来了复杂性,迁移仍然是必要的。
来自 Uber 的 Anshuman Mishra 和 Kaushik Vejju 指出:
在这种规模下,确定性转换工具对于确保一致性至关重要。
Uber 工程师指出,生成式 AI 在自定义测试用例中生成的结果存在不一致的情况。Uber 的单体存储库包含数十万个与 Bazel 集成的测试,而 Bazel 本身并未提供对 JUnit 5 的原生支持。为了解决这一问题,工程师们首先利用 JUnit Platform 实现了统一的执行模型,使 JUnit 4 和 JUnit 5 测试能够通过 Vintage 和 Jupiter 引擎一起运行。这一兼容层使得迁移工作可以分阶段进行,而且不会打乱现有的工作流程。
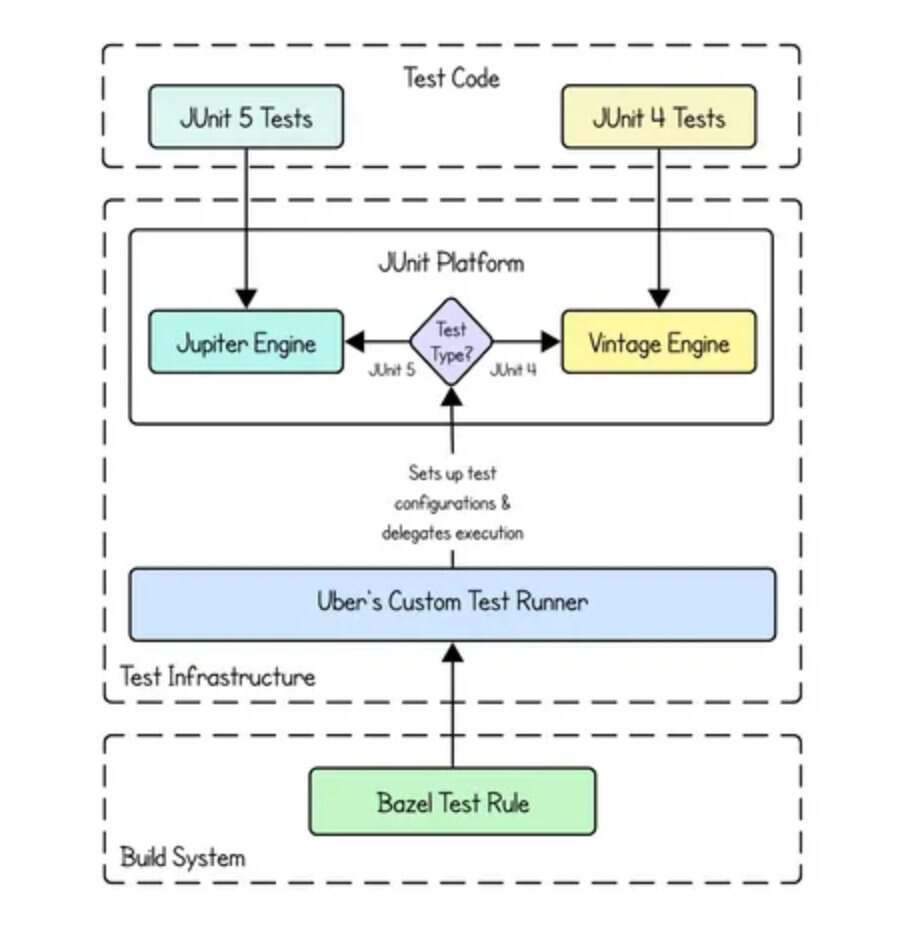
使 JUnit 5 支持 Bazel (图片来源: Uber 博客)
在构建了执行基础后,Uber 采用 OpenRewrite 来实现源代码变更的自动化。OpenRewrite 基于代码的语义表示进行操作,能够将 JUnit 4 API 确定性地转换为等效的 JUnit 5 实现。工程师们定义了转换规则,用于更新注解、替换旧版规则,并将参数化测试模式转换为 JUnit Jupiter 结构。
为了支持内部测试模式,团队针对 Uber 特有的测试运行器和基类,对这些模板进行了扩展,并添加了自定义转换。他们引入了先决条件检查,目的是避免测试文件迁移不完全,并确保将不受支持的模式排除在自动更新之外。工程师们还分析了整个代码库的使用模式,优先处理高频结构,提高了自动化覆盖率和效率。
大规模执行通过一个名为 Shepherd 的内部编排系统进行管理,该系统能够并行对数千个 Bazel 目标应用转换操作。Shepherd 会生成代码差异,并通过持续集成管道(包括单元测试和集成测试的执行)对其进行验证,从而在接受更改之前确保行为正确性。
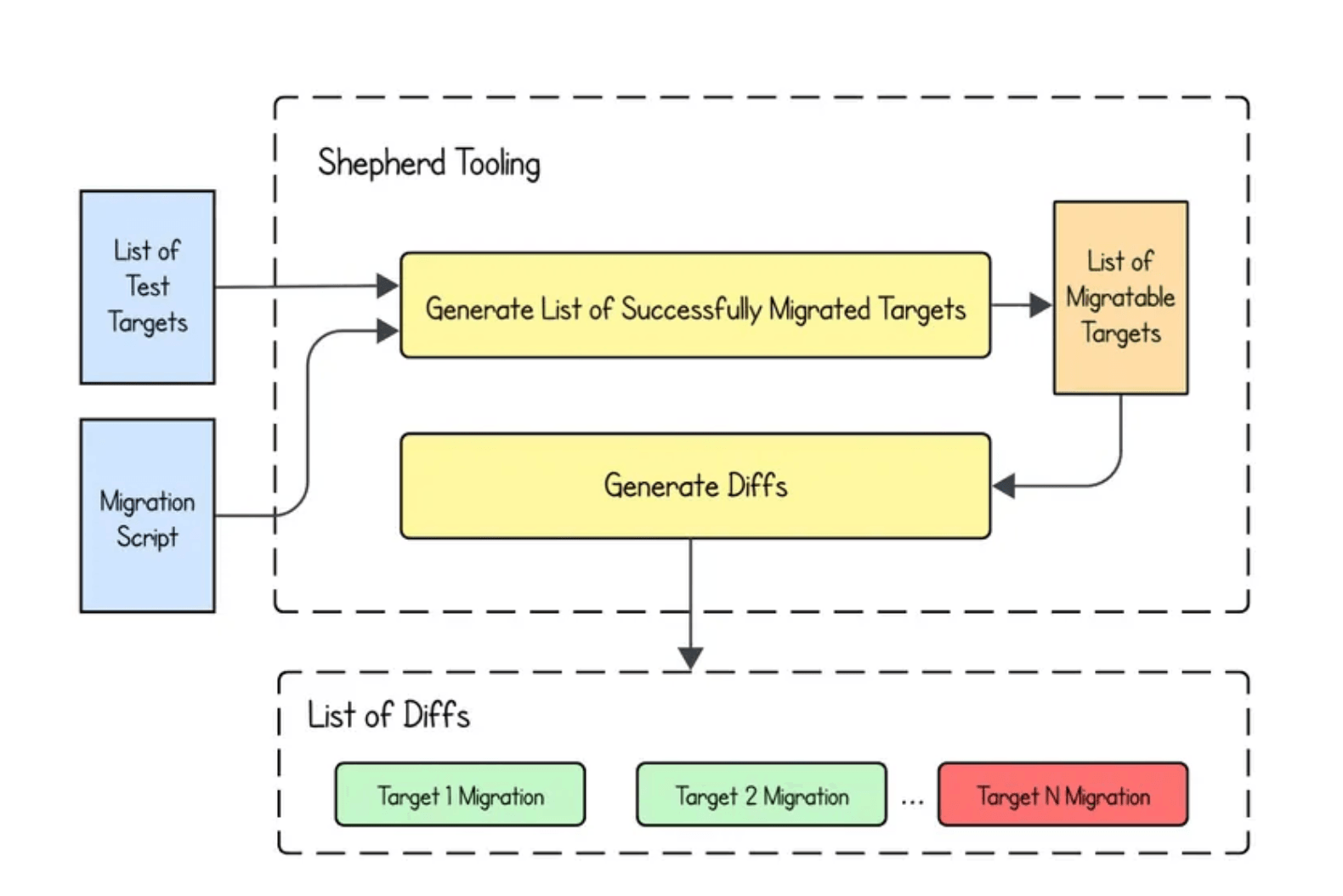
通过 Shepherd 自动生成差异(图片来源: Uber 博客)
此次迁移采用了迭代部署模式。初始运行出现了构建和测试失败的情况,为更新转换逻辑提供了依据。经过多次迭代,自动化覆盖率得到提升,从而使他们能够在几乎无需人工干预的情况下迁移更大的代码库部分。
Uber 工程师表示,此次迁移为利用 OpenRewrite 进行大规模转换奠定了基础。当前进行中的工作包括将其集成到 Bazel 中以支持 Spring Boot 3 的构建,并将 Guava 迁移至标准 Java API,同时将 Joda-Time 迁移至 java.time。
原文链接:
https://www.infoq.com/news/2026/04/uber-junit4-junit5-migration/