Meta 离职大佬田渊栋官宣创业,估值超 300 亿
过去一年,如果要评选硅谷 AI 圈最魔幻的公司,Meta 大概率能稳坐前排。
小扎一边拿出数百亿美元继续豪赌 AI,另一边又对内部组织架构频繁调整、研究团队被不断重组,甚至连那些真正能决定未来技术方向的核心科学家,也在这场“战略摇摆”中被推向门外。
田渊栋就是这场魔幻布局里的典型例子。
昨晚,这位半年前被 Meta 裁掉的华人 AI 科学家田渊栋,带着一家新公司高调归来,首轮融资直接拿下 6.5 亿美元,估值冲到 46.5 亿美元。领投方是 GV 和 Greycroft,AMD 和英伟达都跟投了。
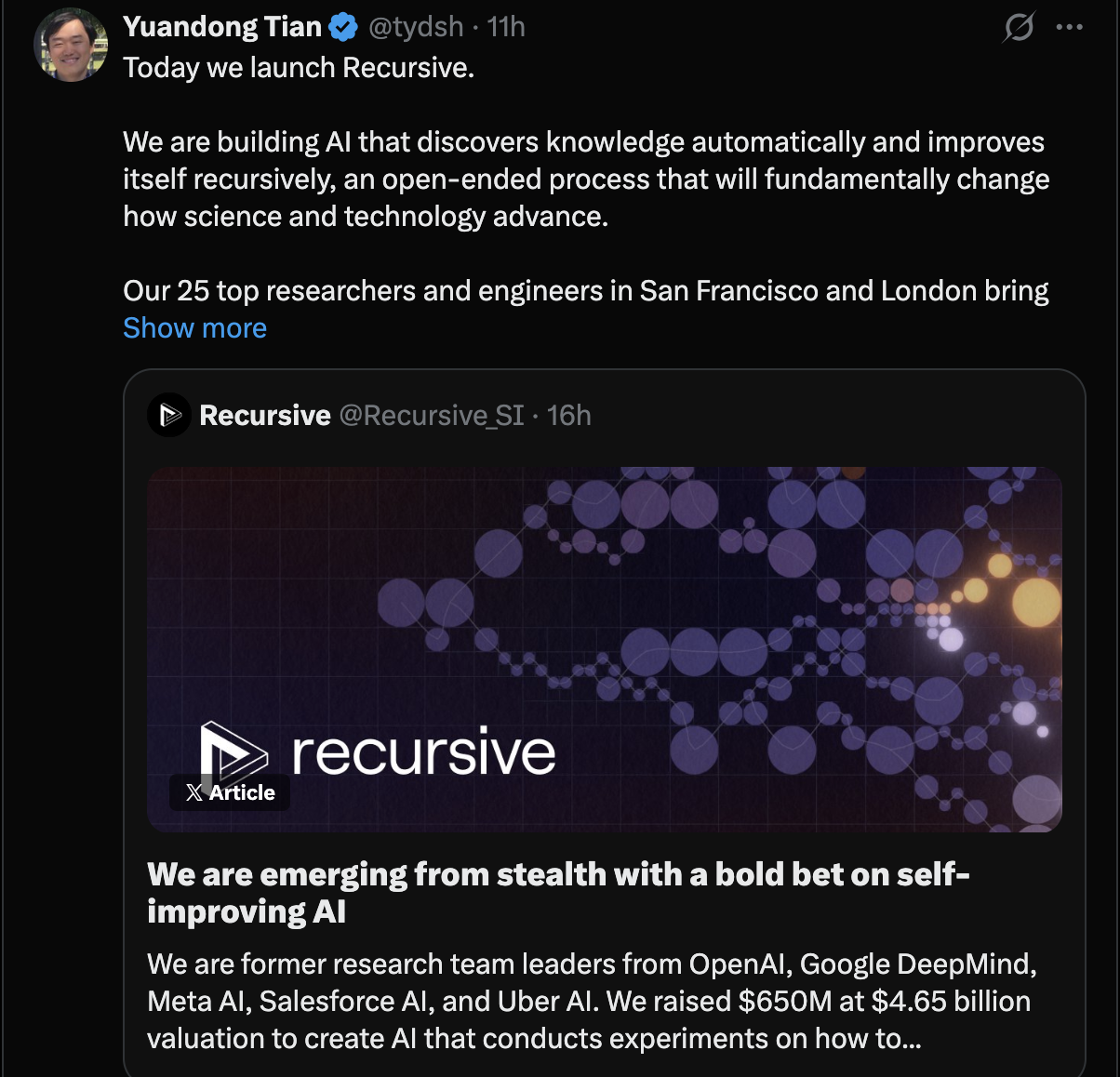
公司名字叫 Recursive Superintelligence。
半年前,这位在 Meta 待了近十年的华人 AI 科学家被裁时,评论区几乎变成了硅谷顶级 AI 公司的“抢人现场”。在他这条离职推文下方的评论区,字节跳动、谷歌 DeepMind 等公司纷纷抛出橄榄枝,但都被他婉拒了。

有趣的是,当时还有人调侃,提议田应该召集所有以前在 Meta 的人,自己开一家公司,然后狠狠地报复 Meta。
或许看到这条评论后,他心动了。
田渊栋是谁?
他出生于上海,毕业于上海交大,随后在 Carnegie Mellon University 机器人研究所拿下博士学位。博士毕业后,他进入 FAIR,在 Meta 一待接近十年。他长期担任 NeurIPS、ICML 等顶会领域主席,是学界和工业界都认可的核心研究者。
他的研究方向,几乎踩在了当代 AI 最核心的交叉点上:强化学习、多智能体系统、大模型推理规划、深度学习理论分析、AI 可解释性。他长期担任 NeurIPS、ICML 等顶会领域主席,是业内公认的“偏理论、偏底层、偏难题”的那类研究者。
这种人,在大厂体系里通常有点尴尬。他们不一定能快速交付 flashy demo,也未必适合冲 KPI,但往往决定了一家公司未来三到五年的技术天花板。
偏偏这几年,Meta 对这种长期主义的耐心越来越少。田渊栋的离职,就是这种缺少长期主义耐心带来的公司动荡的缩影。
2025 年初,距离 Llama 4 发布只剩不到两个月,Meta 内部突然调整资源配置,将 FAIR 的部分基础研究团队直接抽调到生成式 AI 产品线。包括田渊栋团队在内,大量研究人员被要求承担后训练、调参、问题修复等工程支持任务。
这场调整背后,是 Meta AI 内部越来越明显的路线转向:从长期基础研究,转向短周期产品交付。
随着 Meta AI 权力结构调整,以及 Alexandr Wang 主导的新组织扩张,FAIR 的独立性被进一步压缩。最终,在一次大规模组织收缩中,田渊栋及其团队被裁撤。
他当时在社交平台写下的那句:“真正该解决问题的人,并不是被裁掉的人。”
带着失望离开半年后,田渊栋带着新公司又重新“杀回”了 AI 圈。
大厂“出走”的 AI 老兵,组了个豪华牌局
Recursive 创始团队几乎像是一整个“硅谷 AI 梦之队”,这 8 位创始人把当前 AI 产业链上最核心的研究机构凑了个遍:OpenAI、Google DeepMind、Meta AI、Salesforce AI、Uber AI。

站在台前的是 CEO Richard Socher。AI 圈对这个名字并不陌生。Socher 曾担任 Salesforce 首席科学家,负责 Salesforce AI 整体研究业务,后来创办搜索公司 You.com。他属于那种典型的硅谷“学术派创业者”——既有论文履历,也有商业化经验。
另一位关键人物是 Caiming Xiong,他曾在 Salesforce 主导多模态预训练研究。此外,还有多位从 OpenAI 出走的研究员,包括 Josh Tobin、Jeff Clune、Tim Shi。
甚至连 AI 教科书《Artificial Intelligence: A Modern Approach》作者、Google 前研究总监 Peter Norvig 也加入了顾问阵容。
团队规模目前只有 25 人,这和许多硅谷的典型叙事一样:用最少的人,押注最远的未来。

他们到底在做什么?
那这么多技术大佬凑在一起,他们打算做什么?
今天的大模型竞争,本质上仍然停留在一个简单粗暴的逻辑上:更大的模型、更多的数据、更强的算力,业内把这套方法叫 Scaling Law。
它确实带来了过去几年的爆炸式突破。但问题也越来越明显:边际收益正在下降,训练成本却在指数级上升。Recursive 想做的,恰恰是跳出这条老路。
其实他们想做的事已经把答案写在了公司名字里:Recursive。“递归”,是 Recursive 想解决的核心问题。他们押注的方向叫 Recursive Self-Improvement(递归自我改进)。
简单说,就是让 AI 自己发现问题、优化模型、生成新训练路径,再反过来提升自身能力。这不是做一个更聪明的聊天机器人,也不是继续沿着“大模型参数翻倍”的老路堆算力。他们想做的是——让 AI 具备某种“自我进化能力”。
Socher 对外的解释非常直接:“AI 本身是代码,而 AI 已经能写代码。条件已经成熟。”
这句话背后的逻辑其实很清楚:如果一个系统能理解自己的结构、识别瓶颈、生成优化方案,并验证结果,那它理论上就具备了持续提升自己的可能。
那它和其他 AGI 创业公司有什么不同?
最近一年,硅谷冒出了不少瞄准 AGI 的新实验室。例如 Safe Superintelligence 押注“安全优先”的超级智能;一些新兴实验室则在探索世界模型与强化学习路线。
但 Recursive 的打法更彻底。它跳过了很多公司正在专注研究的如何让模型更聪明这一方向,直接去研究如何让整个 AI 开发流程自动化。
Recursive 目前在 San Francisco 和伦敦设有办公室,接下来,这笔融资将主要用于建设大规模算力基础设施,并启动首个“L1 级自主训练系统”。
按照计划,这套系统将在 2026 年中期亮相。它的目标不止是提升 AI 模型能力。更长远看,它希望把这套递归优化机制扩展到药物发现、科学研究等更广泛领域。
如果它真的成功,影响将远超又一个聊天机器人。而届时,Meta 也许会再一次面对那个熟悉的问题:
为什么自己总能在最关键的时候,把真正值得下注的人送出去?
参考链接:
https://x.com/Recursive_SI/status/2054490801972166898
https://techfundingnews.com/uk-ai-startup-recursive-hits-4-65b-valuation-with-650m-raise-from-nvidia-and-gv/
https://x.com/tydsh/status/1981167436859920861